10장 모델 설계하기
1. 모델의 정의
‘폐암 수술 환자의 생존율 예측하기’의 딥러닝 코드를 다시 한번 옮겨 보면 다음과 같다.
코드의 각 부분에 대한 주석을 추가하였다.
# -*- coding: utf-8 -*-
# 코드 내부에 한글을 사용할 수 있도록 설정하는 부분
# TensorFlow의 Keras 모듈에서 딥러닝 모델을 생성하는 데 필요한 클래스를 불러온다.
from tensorflow.keras.models import Sequential # Sequential 모델을 사용하기 위한 클래스
from tensorflow.keras.layers import Dense # 완전 연결(Dense) 레이어를 사용하기 위한 클래스
# 추가적인 라이브러리 불러오기
import numpy as np # 행렬 연산 및 데이터 처리를 위한 라이브러리
import tensorflow as tf # TensorFlow를 활용하여 딥러닝을 실행하기 위한 라이브러리
# 실행할 때마다 같은 결과를 얻기 위해 랜덤 시드를 설정한다.
np.random.seed(3) # NumPy에서 난수를 고정하는 시드 값 설정
tf.random.set_seed(3) # TensorFlow에서 난수를 고정하는 시드 값 설정
# 준비된 수술 환자 데이터를 불러온다.
# 데이터셋 파일 "ThoraricSurgery.csv"를 로드하고, 각 데이터를 쉼표(,)를 기준으로 분리한다.
Data_set = np.loadtxt("../dataset/ThoraricSurgery.csv", delimiter=",")
# 입력 데이터(X)와 타깃 데이터(Y)를 분리하여 저장한다.
# X: 수술 환자의 다양한 기록 (0번째 열부터 16번째 열까지의 데이터)
# Y: 수술 후 생존 여부를 나타내는 결과 값 (17번째 열)
X = Data_set[:,0:17] # 입력 데이터 (환자의 특성 17개)
Y = Data_set[:,17] # 출력 데이터 (생존 여부, 0 또는 1)
# 딥러닝 모델을 생성한다.
# Sequential 모델을 사용하여 신경망을 구성한다.
model = Sequential()
# 입력층과 첫 번째 은닉층을 추가한다.
# - 노드 개수: 30개
# - 입력 차원: 17개 (환자의 특성 개수)
# - 활성화 함수: ReLU (Rectified Linear Unit, 비선형성을 추가하여 학습을 용이하게 함)
model.add(Dense(30, input_dim=17, activation='relu'))
# 출력층을 추가한다.
# - 노드 개수: 1개 (이진 분류 문제이므로 1개의 출력 노드 사용)
# - 활성화 함수: 시그모이드(sigmoid) (출력값을 0과 1 사이의 확률로 변환)
model.add(Dense(1, activation='sigmoid'))
# 모델을 컴파일한다.
# - 손실 함수: binary_crossentropy (이진 분류 문제이므로 크로스엔트로피 사용)
# - 옵티마이저: Adam (경사 하강법을 기반으로 한 최적화 알고리즘)
# - 평가 지표: 정확도 (accuracy) 사용
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델을 학습시킨다.
# - 입력 데이터(X)와 출력 데이터(Y)를 사용하여 학습
# - 총 100번의 에포크(epochs) 동안 학습 진행 (데이터를 100번 반복하여 학습)
# - 배치 크기(batch_size): 10 (한 번에 10개의 데이터를 학습한 후 가중치를 업데이트)
model.fit(X, Y, epochs=100, batch_size=10)이 코드에서 데이터를 불러오고 다루는 부분은 앞서 살펴본 내용이므로, 여기서는 실제로 딥러닝이 수행되는 과정을 더 자세히 이해해 보겠다. 딥러닝 모델을 설정하고 구동하는 과정은 model이라는 객체를 선언하면서 시작된다. 이 객체는 신경망의 구조를 정의하고 학습을 수행하는 핵심 역할을 한다.
딥러닝이 진행되는 과정은 크게 세 단계로 나눌 수 있다.
먼저, model = Sequential()로 시작하는 부분은 딥러닝의 전체 구조를 설계하고 층을 설정하는 과정이다. 신경망은 여러 개의 층(layer)으로 구성되며, 입력층, 은닉층, 출력층이 순차적으로 연결된다. Sequential()을 사용하면 이러한 층을 순서대로 쌓아갈 수 있다.
그다음, model.compile()은 앞에서 정의한 신경망 모델을 컴퓨터가 실제로 연산할 수 있도록 변환하는 과정이다. 이 과정에서는 손실 함수(loss function), 최적화 알고리즘(optimizer), 그리고 학습 성능을 평가할 지표(metrics)를 설정하게 된다. 손실 함수는 신경망이 예측한 결과와 실제 값 사이의 차이를 계산하는 기준이 되며, 최적화 알고리즘은 이 차이를 줄이기 위해 가중치를 조정하는 방법을 결정한다.
마지막으로 model.fit()을 실행하면 신경망이 실제 데이터를 학습하게 된다. 입력 데이터와 출력 데이터를 사용하여 지정된 횟수(epochs) 동안 반복 학습하며, 한 번에 처리할 데이터의 크기(batch size)를 설정하여 학습 속도를 조절할 수 있다. 학습이 진행되면서 모델은 점점 더 정확한 예측을 할 수 있도록 가중치를 조정하게 된다.
이제부터 이 세 가지 과정이 어떻게 동작하는지 자세히 살펴보겠다.
2. 입력층, 은닉층, 출력층
먼저 딥러닝의 구조를 짜고 층을 설정하는 부분을 살펴보면 다음과 같다.
# 딥러닝 모델을 생성한다.
# Sequential 모델을 사용하여 신경망을 구성한다.
model = Sequential()
# 입력층과 첫 번째 은닉층을 추가한다.
# - 노드 개수: 30개
# - 입력 차원: 17개 (환자의 특성 개수)
# - 활성화 함수: ReLU (Rectified Linear Unit, 비선형성을 추가하여 학습을 용이하게 함)
model.add(Dense(30, input_dim=17, activation='relu'))
# 출력층을 추가한다.
# - 노드 개수: 1개 (이진 분류 문제이므로 1개의 출력 노드 사용)
# - 활성화 함수: 시그모이드(sigmoid) (출력값을 0과 1 사이의 확률로 변환)
model.add(Dense(1, activation='sigmoid'))
딥러닝은 퍼셉트론 위에 여러 개의 은닉층을 추가하여 학습하는 방식이다. 케라스에서는 이러한 층을 쉽게 만들 수 있도록 Sequential() 함수를 제공하며, 이를 활용하면 간단하게 신경망 구조를 정의할 수 있다.
Sequential() 함수를 model이라는 이름으로 선언한 후, model.add()를 사용하면 새로운 층을 추가할 수 있다. 코드에는 model.add()가 두 번 사용되었으므로, 총 두 개의 층이 만들어진다. 마지막 층은 출력층, 그 앞에 있는 층은 은닉층 역할을 한다. 즉, 이 모델은 하나의 은닉층과 하나의 출력층을 가진 신경망이다.
두 번의 model.add()가 사용되었으므로 두 개의 층으로 만들어지며, 각각 출력층과 은닉층의 역할을 한다.
각 층의 세부 구조는 Dense() 함수를 통해 결정된다. 예를 들어, 코드에서 사용된 Dense(30, input_dim=17, activation='relu')를 살펴보면 다음과 같은 의미를 가진다.
- Dense(30): 이 층에 30개의 노드(뉴런)를 생성한다.
- input_dim=17: 입력 데이터에서 17개의 값을 받아서 은닉층의 30개 노드로 전달한다.
- activation='relu': 활성화 함수로 ReLU(Rectified Linear Unit)를 사용하여 비선형성을 추가한다.
케라스에서는 입력층을 따로 만들지 않고, 첫 번째 은닉층을 만들 때 input_dim을 설정하여 입력 데이터를 처리하도록 한다. 따라서 이 코드에서 첫 번째 Dense 층은 입력층과 은닉층을 함께 처리하는 역할을 한다.
이 모델이 처리하는 데이터는 폐암 수술 환자의 생존 여부를 예측하는 데이터로, 각 환자마다 17개의 특성(나이, 건강 상태 등)이 입력값으로 주어진다. 이 17개의 입력 데이터를 30개의 노드가 있는 첫 번째 은닉층으로 보내 학습을 진행하는 방식이다.

신경망에서 은닉층의 각 노드는 17개의 입력 값을 받는다. 입력된 값들은 각각 다른 가중치(숫자)를 가지고 있으며, 이 가중치가 곱해진 후 모두 더해진다. 그리고 이 값을 활성화 함수라는 것을 통과시켜 새로운 결과를 만든다. 이때 활성화 함수는 신경망이 단순한 계산을 넘어서 복잡한 패턴을 학습할 수 있도록 도와준다. 어떤 활성화 함수를 사용할지는 activation이라는 옵션을 통해 정할 수 있다.
이 코드에서는 첫 번째 은닉층에서 ReLU(ReLU, Rectified Linear Unit)라는 활성화 함수를 사용했다. ReLU는 아주 간단한 규칙을 가진 함수인데, 0 이하의 값은 무조건 0으로 만들고, 0보다 큰 값은 그대로 유지하는 방식이다. 이렇게 하면 신경망이 더 효과적으로 학습할 수 있다.
이제 출력층을 살펴보자.
model.add(Dense(1, activation='sigmoid'))
이 코드에서 Dense(1)은 출력 노드의 개수가 1개라는 뜻이다. 출력층에서는 최종적으로 한 개의 값을 만들어야 한다. 이 모델이 예측하는 것은 폐암 수술 후 환자가 생존할 확률이므로, 결과는 0과 1 사이의 숫자로 나와야 한다.
그래서 활성화 함수로 시그모이드(sigmoid)를 사용했다. 시그모이드는 어떤 숫자가 들어오더라도 0과 1 사이의 값으로 변환해 준다. 예를 들어, 어떤 환자의 데이터가 주어졌을 때 모델이 0.8을 출력한다면, 이 환자가 생존할 확률이 80%라는 의미가 된다. 반대로 0.2가 나온다면 생존 확률이 20%라는 뜻이다.
즉, ReLU는 은닉층에서 데이터가 효과적으로 흐르게 도와주는 역할을 하고, 시그모이드는 최종적으로 확률을 출력하는 역할을 한다.
3. 모델 컴파일
다음으로 model.compile 부분을 살펴보자.
# 모델을 컴파일한다.
# - 손실 함수: binary_crossentropy (이진 분류 문제이므로 크로스엔트로피 사용)
# - 옵티마이저: Adam (경사 하강법을 기반으로 한 최적화 알고리즘)
# - 평가 지표: 정확도 (accuracy) 사용
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
딥러닝 모델을 만들었다면, 이를 실제로 동작할 수 있도록 컴파일하는 과정이 필요하다. model.compile() 부분은 앞서 설계한 모델이 제대로 학습할 수 있도록 여러 가지 환경을 설정하는 단계이다.
먼저, 모델이 학습할 때 오차(손실)를 어떻게 측정할 것인지 결정해야 한다. 이를 위해 손실 함수(loss function)를 선택하는데, 손실 함수는 모델이 얼마나 정답과 가까운 예측을 했는지를 계산하는 역할을 한다. 여기서는 우리가 2장에서 배운 평균 제곱 오차 함수 (mean_squared_error) 를 사용한다.
딥러닝에서 손실함수
손실함수는 딥러닝 모델이 예측한 값과 실제 값 사이의 차이를 측정하는 함수로, 모델 학습 과정에서 핵심적인 역할을 합니다. 이를 통해 모델의 성능을 평가하고, 최적화를 위한 방향을 제시한다.

손실함수의 역할
- 오차 측정: 손실함수는 예측값과 실제값 간의 차이를 계산하여 학습 중 모델의 성능을 정량적으로 평가한다.
- 최적화: 경사하강법(Gradient Descent) 등의 알고리즘을 통해 손실값을 최소화하며 모델 매개변수를 업데이트합니다. 손실함수는 미분 가능해야 경사하강법이 효과적으로 작동한다.
- 학습 지표: 손실값이 작아질수록 모델이 더 정확하게 학습되었다고 판단할 수 있다.
손실함수의 종류 : 손실함수는 주로 모델의 목적(회귀 또는 분류)에 따라 선택된다.
딥러닝에서는 정확도 대신 손실함수를 사용하는데, 이는 정확도가 0이 되는 지점에서 기울기가 없어 학습이 멈출 수 있기 때문이다. 반면 손실함수는 기울기가 0이 되지 않도록 설계되어 있어 지속적인 학습이 가능하다.
오차 함수 선택
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
- 평균 제곱 오차(Mean Squared Error, MSE)
- 주로 회귀(regression) 문제에서 사용됨
- 예측값과 실제값의 차이를 제곱하여 평균을 내는 방식
- 예시: 키를 예측하는 모델에서 실제 키가 170cm인데 모델이 168cm라고 예측했다면, 오차는 (170 - 168)² = 4가 된다.
- 교차 엔트로피(Cross Entropy)
- 주로 분류(classification) 문제에서 사용됨
- 예측 확률이 정답과 가까울수록 오차가 작아지고, 틀릴수록 오차가 커지도록 설계됨
- 예시: 암 환자의 생존 여부(0 또는 1)를 예측하는 모델에서, 실제 정답이 1(생존)인데 모델이 0.1(10% 확률로 생존)이라고 예측했다면, 매우 큰 오차로 계산됨
이 코드에서는 binary_crossentropy를 사용했다. 이는 이진 분류(0 또는 1을 예측하는 문제)에 적합한 손실 함수이다.
최적화 함수(Optimizer)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
모델이 오차를 줄여가며 점점 더 정확한 예측을 할 수 있도록 도와주는 역할을 한다. 가장 많이 사용되는 최적화 알고리즘 중 하나는 Adam(Adaptive Moment Estimation)이다.
Adam(Adaptive Moment Estimation)은 딥러닝에서 모델을 학습시킬 때 많이 사용하는 최적화 알고리즘이다. 쉽게 말해, 모델이 점점 더 좋은 예측을 할 수 있도록 가중치(파라미터)를 업데이트하는 방법으로, 기본적으로 경사 하강법(Gradient Descent)을 기반으로 한다.
- 학습 속도를 자동으로 조정 : Adam은 각 파라미터(가중치)마다 알아서 학습률(learning rate)을 조정해준다. 즉, 어떤 파라미터는 빨리, 어떤 파라미터는 천천히 업데이트해서 더 효과적으로 학습한다.
- 모멘텀 사용 : 이전에 계산한 그래디언트(기울기)를 참고해서 현재 방향을 정한다. 이렇게 하면 학습이 더 부드럽게 진행되고, 최적의 값에 빠르게 도달할 수 있다.
- 효율적이고 빠름 : 계산이 간단하고 메모리를 적게 사용해서, 큰 데이터나 복잡한 모델에서도 잘 작동한다.
- 노이즈와 희소 데이터에 강함 : 데이터가 불안정하거나 부족한 경우에도 안정적으로 학습할 수 있다.
- 초기 설정으로도 잘 작동 : Adam은 기본 설정만으로도 대부분의 문제에서 좋은 성능을 낸다. 그래서 따로 복잡하게 조정하지 않아도 된다.
Adam은 마치 산을 내려가는 등산가와 같다.
- 등산가는 현재 위치와 경사를 보면서 어디로 가야 할지 결정한다(그래디언트 계산).
- 이전에 걸었던 길을 참고해서 너무 급하게 가지 않고 부드럽게 이동한다(모멘텀 사용).
- 길이 험하거나 평평한 곳에서는 속도를 조절하며 효율적으로 움직인다(적응형 학습률).
평가 지표(metrics) 설정
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
metrics=['accuracy']는 학습 중 모델의 성능을 평가하는 기준을 설정하는 부분이다. 여기서는 정확도(accuracy)를 사용했다.
metrics 설정은 단순히 학습 과정에서 모델이 얼마나 잘 동작하는지 확인하는 용도로 사용되며, 학습에는 직접적인 영향을 주지는 않는다.
- 예를 들어, 100개의 데이터를 테스트했을 때 90개를 맞췄다면 정확도는 90%가 된다.
- 정확도 외에도 precision, recall, f1-score 등의 다양한 평가 지표를 사용할 수 있다.

4. 교차 엔트로피
딥러닝에서 모델의 성능을 평가하는 중요한 요소 중 하나가 오차 함수(loss function)이다. 오차 함수는 모델이 예측한 값과 실제 값 사이의 차이를 계산하여, 모델이 얼마나 정확한 예측을 했는지 측정하는 역할을 한다. 특히 교차 엔트로피(cross entropy)는 분류(classification) 문제에서 많이 사용되는 오차 함수이다. 예측해야 할 값이 두 가지(예: 참 또는 거짓, 생존 또는 사망)일 때는 binary_crossentropy(이항 교차 엔트로피)를 사용한다.
지금 구현하는 모델은 폐암 수술 후 환자의 생존 여부(0 또는 1)를 예측하는 이진 분류 문제이므로, binary_crossentropy를 사용하는 것이 적절하다. 기존 코드에서 mean_squared_error 대신 binary_crossentropy를 사용하면 모델의 예측 정확도(accuracy)가 향상되는 것을 확인할 수 있다.
케라스에서는 다양한 오차 함수를 간단하게 적용할 수 있으며, 대표적인 오차 함수는 다음과 같다.
| 오차 함수 | 설명 | 계산식 |
| 평균 제곱 오차 (MSE, Mean Squared Error) |
예측 값과 실제 값의 차이를 제곱하여 평균을 구하는 방식. 주로 회귀 문제에서 사용됨. | mean(square(yt - yo)) |
| 평균 절대 오차 (MAE, Mean Absolute Error) |
예측 값과 실제 값의 차이의 절댓값을 평균낸 값. | mean(abs(yt - yo)) |
| 평균 절대 백분율 오차 (MAPE, Mean Absolute Percentage Error) |
예측 오차를 실제 값으로 나누어 백분율 형태로 나타낸 오차. | mean(abs(yt - yo)/abs(yt)) |
| 평균 제곱 로그 오차 (MSLE, Mean Squared Logarithmic Error) |
실제 값과 예측 값에 로그를 적용한 후 차이를 제곱하여 평균을 구하는 방식. | mean(square((log(yo) + 1) - (log(yt) + 1))) |
교차 엔트로피 계열 (분류 문제에서 사용)은 다음과 같다.
| categorical_crossentropy | 여러 개의 클래스를 분류할 때 사용(예: 개, 고양이, 토끼 중 하나를 예측). |
| binary_crossentropy | 두 개의 클래스(예: 생존/사망, 스팸/정상)를 분류할 때 사용. |
5. 모델 실행하기
딥러닝 모델을 정의하고 컴파일한 후에는 데이터를 학습시켜야 한다. 이를 위해 model.fit() 함수를 사용한다. 이 함수는 앞서 설정한 환경을 기반으로 주어진 데이터를 모델에 입력하고, 모델이 예측을 수행하며 가중치를 조정하는 과정을 반복한다.
이 과정을 이해하기 위해 먼저 몇 가지 용어를 정리해 보겠다.
- 속성(attribute): 데이터의 각 특성을 의미한다. 이 모델에서는 폐암 수술 환자의 생존 여부를 예측하기 위해 17개의 정보를 사용하므로, 각 환자의 데이터는 17개의 속성을 가진다.
- 샘플(sample): 하나의 데이터 행(row)을 의미한다. 즉, 하나의 환자 정보가 하나의 샘플이 된다. 주어진 데이터에는 총 470명의 환자 데이터가 있으므로, 470개의 샘플이 존재한다.
- 클래스(class): 분류해야 할 결과값을 의미한다. 이 모델에서는 환자의 생존 여부(0 또는 1)가 클래스가 된다.
학습 과정 개념 정리
에포크(epoch)
- 에포크(epoch)란 모델이 주어진 데이터를 처음부터 끝까지 한 번 학습하는 과정을 의미한다.
- 코드에서 epochs=100으로 설정하면, 모든 샘플을 100번 반복 학습한다는 뜻이다.
- 에포크 수가 너무 작으면 학습이 충분히 이루어지지 않을 수 있고, 너무 크면 과적합(overfitting)이 발생할 가능성이 있다.
배치 크기(batch size)
- 배치 크기(batch size)란 한 번에 학습할 샘플의 개수를 의미한다.
- 코드에서 batch_size=10으로 설정하면, 470개의 샘플을 10개씩 묶어서 학습을 진행한다는 뜻이다.
- 배치 크기가 너무 크면 학습 속도가 느려지고, 너무 작으면 편차가 커져 학습이 불안정해질 수 있다. 따라서 적절한 배치 크기를 선택하는 것이 중요하다.
# 모델을 학습시킨다.
# - 입력 데이터(X)와 출력 데이터(Y)를 사용하여 학습
# - 총 100번의 에포크(epochs) 동안 학습 진행 (데이터를 100번 반복하여 학습)
# - 배치 크기(batch_size): 10 (한 번에 10개의 데이터를 학습한 후 가중치를 업데이트)
model.fit(X, Y, epochs=100, batch_size=10)
> X, Y: 학습에 사용될 입력 데이터(X)와 정답 데이터(Y)를 의미한다.
> epochs=100: 모델이 데이터를 100번 반복하여 학습한다.
> batch_size=10: 한 번 학습할 때 10개의 샘플을 사용하고, 이후 가중치를 업데이트한다.
11장. 데이터 다루기
1. 딥러닝과 데이터
머신러닝과 딥러닝은 방대한 데이터를 학습하여 사람처럼 판단하고 예측하는 기술이다. 하지만 데이터의 양이 많다고 해서 항상 좋은 결과를 얻을 수 있는 것은 아니다. 더 중요한 것은 우리가 원하는 정보를 정확히 담고 있는 ‘필요한’ 데이터를 얼마나 확보했는가이다.
예를 들어, 어떤 사람이 건강한 식습관이 비만 예방에 미치는 영향을 연구한다고 가정해 보자. 이때 단순히 모든 사람의 식단 데이터를 수집하는 것보다, 비만 여부와 관련이 있는 사람들의 식습관 데이터를 선별하는 것이 훨씬 중요하다. 또한, 데이터가 왜곡되지 않고, 불필요한 정보가 포함되지 않은 상태여야 한다.
머신러닝과 딥러닝에서 데이터 전처리의 중요성
머신러닝과 딥러닝 프로젝트에서 가장 중요한 첫 단계는 데이터를 분석하고 정제하는 과정이다.
데이터가 올바르게 준비되지 않으면 아무리 좋은 모델을 사용하더라도 제대로 된 결과를 얻을 수 없다.
| 데이터의 목적성 | 예를 들어, 당뇨병 예측 모델을 만든다면 혈당 수치, 체질량 지수(BMI), 가족력 등의 관련 데이터를 포함해야 한다. 반면, 혈액형이나 출생지는 당뇨병과 관계가 없을 가능성이 높으므로 불필요한 데이터일 수 있다. |
| 데이터의 편향성 | 예를 들어, 건강한 사람의 데이터만 포함되어 있고, 당뇨병 환자의 데이터가 부족하다면 모델은 당뇨병을 제대로 예측하지 못할 것이다. |
| 데이터의 전처리 | 숫자로 변환되지 않은 텍스트 데이터는 숫자로 바꿔야 하며, 결측값(비어 있는 값)이 있다면 적절한 방식으로 채우거나 제거해야 한다. |
2. 피마 인디언 데이터 분석
비만은 유전적인 요인이 클까, 아니면 생활습관의 영향이 더 클까? 이 질문에 대한 좋은 사례가 피마 인디언(Pima Indian) 부족의 건강 데이터이다. 피마 인디언은 1950년대까지만 해도 비만 환자가 거의 없는 부족이었다. 하지만 이후 서구식 패스트푸드 문화가 도입되면서 부족 전체의 50%가 비만, 당뇨병 환자 비율이 30% 이상으로 급격히 증가했다.
이러한 변화는 피마 인디언이 가진 유전적인 특성과 환경적인 요인이 결합하여 발생한 문제라고 할 수 있다. 그들의 유전자는 과거 식량이 부족했던 환경에 적응하여 체내에 영양분을 효율적으로 저장하는 특성을 갖게 만들었다. 하지만 고열량의 패스트푸드와 가공식품을 쉽게 섭취할 수 있는 환경이 되면서, 이 유전적인 특성이 오히려 비만과 당뇨병을 증가시키는 요인이 되어 버렸다.
이러한 피마 인디언 부족을 대상으로 당뇨병 여부를 측정한 데이터셋이 제공되어 있으며, 이를 통해 당뇨병 예측 모델을 학습할 수 있다.
- 데이터 개수: 총 768명의 인디언 데이터 포함
- 속성(feature) 개수: 8개의 건강 정보
- 클래스(class) 개수: 1개의 목표 값(당뇨병 유무)
데이터에는 환자의 혈당 수치, 체질량 지수(BMI), 나이, 임신 횟수 등의 정보가 포함되어 있으며, 마지막 컬럼은 당뇨병 여부(0 또는 1)를 나타낸다.
| 샘플 수 | 768 |
| 속성(Feature) 개수 | 8 |
| 클래스(Class) 개수 | 1 (당뇨병 여부) |
데이터 속성 설명
| 속성명 | 설명 | 단위 |
| Pregnancies | 과거 임신 횟수 | 회 |
| Plasma glucose | 포도당 부하 검사 2시간 후 공복 혈당 농도 | mg/dL |
| Blood Pressure | 확장기 혈압 | mmHg |
| Skin Thickness | 삼두근 피부 주름 두께 | mm |
| Insulin | 혈청 인슐린 (2시간 후) | mu U/ml |
| BMI | 체질량 지수 (몸무게 / 키²) | kg/m² |
| Diabetes Pedigree | 당뇨병 가족력 지수 | - |
| Age | 나이 | 세 |
클래스(Label) 설명
| 클래스 값 | 설명 |
| 0 | 당뇨 아님 |
| 1 | 당뇨 있음 |
데이터 예시 (샘플 일부)
| 샘플 | Pregnancies | Plasma | Blood Pressure | Skin Thickness | Insulin | BMI | Diabetes Pedigree | Age | 당뇨 여부 |
| 1번째 | 6 | 148 | 72 | 50 | - | - | - | - | 1 |
| 2번째 | 1 | 85 | 66 | 31 | - | - | - | - | 0 |
| 3번째 | 8 | 183 | 64 | 32 | - | - | - | - | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 768번째 | 1 | 93 | 70 | 23 | - | - | - | - | 0 |
3. pandas를 활용한 데이터 조사
딥러닝을 다루는 첫 번째 단계는 데이터를 정확하게 파악하는 것이다.
데이터가 크고 정보량이 많아질수록 데이터를 효과적으로 분석하고 활용하는 방법이 필수적이다. 이때 가장 유용한 방법이 데이터를 시각화하여 한눈에 확인하는 것이다.
데이터를 다룰 때는 전문적인 라이브러리를 활용하는 것이 효율적이다. 파이썬에서는 데이터를 처리할 때 pandas 라이브러리를 사용하면 편리하다. 데이터셋을 불러오기 위해 read_csv() 함수를 사용한다. 이때 데이터 파일에는 헤더(header, 데이터 속성명)가 포함될 수도 있고, 없을 수도 있다. 만약 헤더가 없는 데이터셋이라면, names 옵션을 사용하여 직접 속성명을 지정할 수 있다.
# -*- coding: utf-8 -*-
# 코드 내부에 한글을 사용가능 하게 해주는 부분입니다.
# pandas 라이브러리를 불러옵니다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 피마 인디언 당뇨병 데이터셋을 불러옵니다. 불러올 때 각 컬럼에 해당하는 이름을 지정합니다.
df = pd.read_csv('../dataset/pima-indians-diabetes.csv',
names = ["pregnant", "plasma", "pressure", "thickness", "insulin", "BMI", "pedigree", "age", "class"])
1. 데이터 구조 확인
데이터셋의 전체적인 구조를 확인하기 위해 info() 함수를 사용한다.
print(df.info())<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pregnant 768 non-null int64
1 plasma 768 non-null int64
2 pressure 768 non-null int64
3 thickness 768 non-null int64
4 insulin 768 non-null int64
5 BMI 768 non-null float64
6 pedigree 768 non-null float64
7 age 768 non-null int64
8 class 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
None
2. 데이터의 기본 통계 정보 확인
데이터의 평균, 최댓값, 최솟값 등을 확인하려면 describe() 함수를 사용한다.
> 평균(mean)과 표준편차(std)를 통해 데이터의 대략적인 분포를 파악할 수 있다.
> 최솟값(min)과 최댓값(max)을 확인하여 이상치(outlier)가 존재하는지 확인할 수 있다.
> 중앙값(50%), 백분위(25%, 75%)를 통해 데이터의 분포를 확인할 수 있다.
print(df.describe())pregnant plasma pressure thickness insulin BMI \
count 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578
std 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160
min 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000
max 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000
pedigree age class
count 768.000000 768.000000 768.000000
mean 0.471876 33.240885 0.348958
std 0.331329 11.760232 0.476951
min 0.078000 21.000000 0.000000
25% 0.243750 24.000000 0.000000
50% 0.372500 29.000000 0.000000
75% 0.626250 41.000000 1.000000
max 2.420000 81.000000 1.000000
데이터셋에서 특정 속성만 확인하고 싶다면, 해당 컬럼만 선택하여 출력할 수 있다.
예를 들어, 임신 횟수(Pregnancies)와 당뇨병 발병 여부(Outcome)만 확인하려면 다음과 같이 입력한다.
print(df[['Pregnancies', 'Outcome']])4. 데이터 가공
딥러닝을 활용하기 위해서는 데이터를 가공하고 시각적으로 표현하는 과정이 필수적이다.
단순히 많은 데이터를 나열하는 것만으로는 의미를 찾기 어렵기 때문에, 데이터를 정리하고 분석할 수 있도록 가공하는 과정이 필요하다.\
데이터를 가공할 때 중요한 점은 프로젝트의 목적을 잊지 않는 것이다. 이번 프로젝트의 목표는 당뇨병 발병 여부를 예측하는 것이므로,
모든 데이터는 당뇨병 발병과 어떤 관계가 있는지를 중심으로 다루어야 한다. 예를 들어, 임신 횟수(Pregnancies)와 당뇨병 발병 여부(Outcome)의 관계를 분석할 수 있다.
1.1 그룹별 평균 계산
groupby() 함수를 활용하여 임신 횟수에 따른 평균 당뇨병 발생률을 계산할 수 있다. groupby() 함수는 특정 컬럼을 기준으로 데이터를 그룹화한 뒤, 평균, 합계, 개수, 최대/최소값 등의 연산을 적용할 수 있다.
이를 출력하면 다음과 같이 임신 횟수당 당뇨병 발병 확률을 구할 수 있다.
DataFrame.groupby(by, as_index=True).연산()
- by → 그룹화할 기준이 되는 컬럼 : 같은 임신 횟수를 가진 데이터를 하나의 그룹으로 묶음
- as_index → True이면 그룹화한 컬럼을 새로운 인덱스로 설정 / as_index=False → 그룹화한 컬럼을 인덱스로 설정하지 않음
- ['Outcome'].mean() → 그룹별 Outcome의 평균값을 계산
- 연산() → mean(), sum(), count(), max(), min() 등
# 임신 횟수별 당뇨병 발병 확률 계산
grouped_df = df[['pregnant', 'class']].groupby(['pregnant'], as_index=False).mean()
# 임신 횟수를 기준으로 오름차순 정렬
grouped_df = grouped_df.sort_values(by='pregnant', ascending=True)
# 결과 출력
print(grouped_df)pregnant class
0 0 0.342342
1 1 0.214815
2 2 0.184466
3 3 0.360000
4 4 0.338235
5 5 0.368421
6 6 0.320000
7 7 0.555556
8 8 0.578947
9 9 0.642857
10 10 0.416667
11 11 0.636364
12 12 0.444444
13 13 0.500000
14 14 1.000000
15 15 1.000000
16 17 1.000000
5. matplotiib를 이용해 그래프로 표현하기
데이터를 보다 효율적으로 분석하려면 시각화 과정이 필수적이다. 단순한 숫자 나열보다는 그래프를 활용하면 데이터의 패턴과 상관관계를 쉽게 확인할 수 있다. 이를 위해 matplotlib와 seaborn 라이브러리를 활용한다.
데이터 속성 간의 상관관계를 분석하려면 히트맵(heatmap)을 활용할 수 있다.
# 데이터 간의 상관관계를 그래프로 표현해 봅니다.
colormap = plt.cm.gist_heat #그래프의 색상 구성을 정합니다.
plt.figure(figsize=(12,12)) #그래프의 크기를 정합니다.
# 그래프의 속성을 결정합니다. vmax의 값을 0.5로 지정해 0.5에 가까울 수록 밝은 색으로 표시되게 합니다.
sns.heatmap(df.corr(),linewidths=0.1,vmax=0.5, cmap=colormap, linecolor='white', annot=True)
plt.show()
히트맵(Heatmap)은 데이터의 패턴과 상관관계를 직관적으로 확인할 수 있도록 색상으로 표현한 시각화 기법으로,두 항목씩 짝을 지은 뒤 각각 어떤 패턴으로 변화하는지를 관찰하는 함수이다. 두 항목이 전혀 다른 패턴으로 변화하고 있으면 0을, 서로 비슷한 패턴으로 변할수록 1에 가까운 값을 출력한다.
1. 데이터 분석 및 상관관계 시각화 : 변수 간 상관관계를 나타내는 상관 행렬을 색상으로 표현하여 데이터의 특성과 관계를 파악.
2. CNN 해석 : 이미지 분류나 객체 탐지 모델에서 CAM 또는 Grad-CAM을 생성해 모델이 주목한 영역을 시각화.
3. 대규모 데이터 패턴 분석 : 로그 데이터나 고객 행동 데이터를 시각화하여 이상치나 패턴을 식별할 때 유용.
4. 모델 성능 평가 : 모델 예측 결과와 실제 값 간의 차이를 히트맵으로 표현하여 성능을 진단.
 |
|
그림 11-2에서 가장 눈여 겨 봐야 할 부분은 당뇨병 발병 여부를 가리키는 class 항목(맨밑)이다.
class 항목을 보면 pregnant부터 age까지 상관도가 숫자로 표시되어 있고, 숫자가 높을수록 밝은 색상으로 채워져 있다. 이를 통해 plasma 항목(공복 혈당 농도)이 class 항목과 가장 상관관계가 높다는 것을 알 수 있다. 즉, 이 공복 혈당 농도가 당뇨병 발병 여부를 결정하는 데 가장 중요한 역할을 한다는 것을 예측할 수 있다.
이제 plasma와 class 항목만 따로 떼어 두 항목 간의 관계를 그래프로 다시 한번 확인해보자.
grid = sns.FacetGrid(df, col='class')
grid.map(plt.hist, 'plasma', bins=10)
plt.show()

이 그래프를 통해 당뇨병 환자(class = 1)의 경우, Plasma 항목(공복 혈당 농도)의 수치가 150 이상인 경우가 많다는 것을 확인할 수 있다. 즉, Plasma 값이 높을수록 당뇨병 발병 가능성이 증가하는 경향이 있음을 시각적으로 확인할 수 있다.
당뇨병 환자(오른쪽)의 경우 비당뇨병 환자(왼쪽)에 비해 공복 혈당 농도의 수치가 150 이상인 경우가 많다.
이처럼 결과에 미치는 영향이 큰 변수(feature)를 찾아내는 과정이 데이터 전처리의 핵심적인 예이다. 데이터 전처리는 딥러닝뿐만 아니라 모든 머신러닝 모델의 성능을 향상시키는 중요한 과정으로, 모델이 학습할 수 있도록 불필요한 데이터를 제거하고, 중요한 데이터를 강조하는 역할을 한다.
6. 피마 인디언의 당뇨병 예측 실행
딥러닝 모델을 실행할 때 동일한 결과를 얻으려면 seed 값을 설정하는 것이 중요하다. 이는 컴퓨터가 완전한 랜덤 값을 생성하는 것이 아니라, 미리 정의된 랜덤 테이블에서 값을 가져오는 방식을 따르기 때문이다.
# 실행할 때마다 같은 결과를 출력하기 위해 설정하는 부분입니다.
numpy.random.seed(3)
tf.random.set_seed(3)
따라서 같은 랜덤 테이블을 불러오기 위해 numpy.random.seed()와 tensorflow.random.set_seed()를 함께 사용한다. 이를 통해 딥러닝 모델을 실행할 때마다 동일한 초기 가중치를 적용할 수 있으며, 재현 가능한 실험 결과를 얻을 수 있다. 다만, 완전히 동일한 결과를 보장할 수는 없다. 내부적으로 사용되는 라이브러리(cuDNN 등)에서 자체적인 랜덤성을 가지기 때문이다.
당뇨병 예측을 위한 딥러닝 모델 구현
이제 케라스를 이용하여 당뇨병을 예측하는 딥러닝 모델을 구현해보자. 이 모델은 이항 분류(binary classification) 문제를 해결하는 데 초점을 맞추고 있다. 즉, 주어진 정보를 바탕으로 환자가 당뇨병에 걸릴 확률이 높은지(1), 낮은지(0)를 예측하는 모델이다.
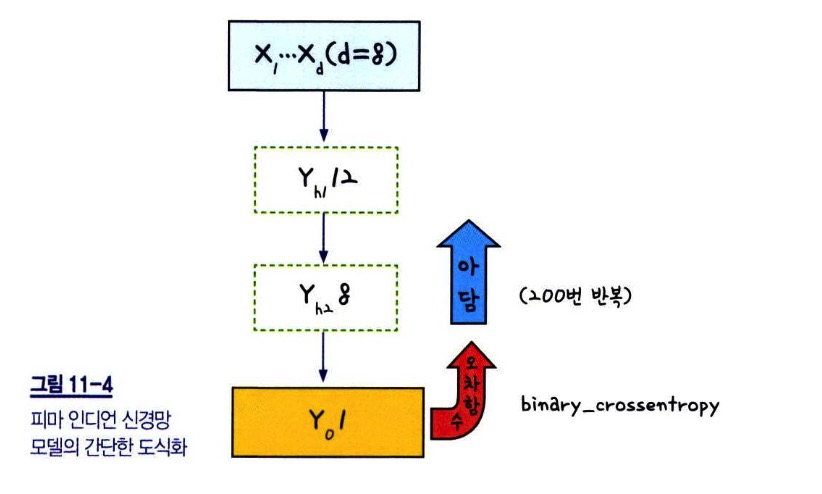
- 입력 데이터(X): pima-indians-diabetes.csv 데이터셋에서 0번째~7번째 열(총 8개 속성)을 사용
- 타겟 데이터(Y): 8번째 열(당뇨병 여부: 0 또는 1)
- 모델 구조
- 입력층: 8개의 입력값(input_dim=8)
- 은닉층 1: 12개의 노드(Dense(12)) + ReLU 활성화 함수 사용
- 은닉층 2: 8개의 노드(Dense(8)) + ReLU 활성화 함수 사용
- 출력층: 1개의 노드(Dense(1)) + 시그모이드(Sigmoid) 활성화 함수 사용
- 오차 함수(loss function): binary_crossentropy (이항 분류 문제이므로 사용)
- 최적화 알고리즘(optimizer): Adam (경사 하강법의 변형 알고리즘으로 널리 사용됨)
- 반복 학습(epoch): 200번 반복
- 배치 크기(batch size): 10개씩 데이터를 학습
약 72.53%의 예측 정확도를 보인다.
12장 다준 분류 문제 해결하기
딥러닝을 이용한 다중 분류 문제는 두 개의 클래스만 존재하는 이항 분류(binary classification)와 달리 세 개 이상의 클래스 중에서 하나를 예측하는 문제를 의미한다. 대표적인 다중 분류 문제로 아이리스(Iris) 품종 예측이 있으며, 이를 통해 다중 분류 문제를 해결하는 방법을 실습해볼 수 있다.
1. 다중 분류 문제
이리스는 우리나라에서 붓꽃이라고도 불리는 꽃이다. 이 꽃은 꽃잎의 길이, 너비, 꽃받침의 길이, 너비 등의 특성에 따라 여러 개의 품종으로 나뉜다. 아이리스 품종 예측 데이터는 dataset/iris.csv 파일에 저장되어 있으며, 딥러닝을 통해 이 데이터를 학습하여 주어진 꽃의 속성값을 기반으로 품종을 예측하는 것이 목표이다.
아이리스 데이터의 주요 특징
- 입력 데이터(속성): 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비 (총 4개)
- 출력 데이터(클래스): Setosa(0), Versicolor(1), Virginica(2) (총 3개)
이전까지 다루었던 문제들은 0과 1 중 하나를 예측하는 이항 분류 문제였다. 하지만 아이리스 데이터는 총 3개의 품종이 있기 때문에 다중 분류 문제(multi-class classification)로 접근해야 한다. 데이터 구조는 다음과 같다:
번호 sepal_length(정보1) sepal_width(정보2) petal_length(정보3) petal_width species(정보4)
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
2. 상관도 그래프
딥러닝을 수행하기 전에 데이터의 패턴과 관계를 파악하는 과정은 매우 중요하다. 특히, 여러 개의 속성이 존재하는 데이터셋에서는 속성 간의 관계를 시각적으로 확인하는 것이 효과적인 분석 방법이 될 수 있다.
이번에는 seaborn 라이브러리의 pairplot() 함수를 이용하여 아이리스 데이터의 상관관계를 한눈에 파악해보겠다.
1. Pairplot의 개념
Pairplot(페어플롯)은 데이터셋의 각 변수(속성) 간 관계를 산점도(scatter plot)와 히스토그램(histogram)으로 나타내는 그래프이다.
특히, 다중 분류 문제에서 각 클래스별 데이터 분포를 비교할 수 있도록 시각화하는 데 유용하다.
Pairplot의 특징
- 데이터의 각 속성(feature)들 간의 관계를 한눈에 확인 가능
- 동일한 속성끼리는 히스토그램으로, 다른 속성 간에는 산점도(scatter plot)로 표현됨
- hue 옵션을 활용하여 클래스별 색상 구분 가능
2. Pairplot을 활용한 아이리스 데이터 분석
# 데이터 입력
df = pd.read_csv('../dataset/iris.csv', names = ["sepal_length", "sepal_width", "petal_length", "petal_width", "species"])
아이리스 데이터는 꽃잎의 길이(petal length), 너비(petal width), 꽃받침의 길이(sepal length), 너비(sepal width)을 포함하고 있으며, 이를 바탕으로 세 가지 품종(Setosa, Versicolor, Virginica)을 분류한다.
| 꽃의 특징 | 꽃의 품종 | |||
| 꽃받침의 길이 (sepal length) |
꽃받침 너비 (sepal width) |
꽃잎의 길이 (petall length) |
꽃잎의 너비 (petal width) |
Setosa |
| Versicolor | ||||
| Virginica | ||||
import seaborn as sns
import matplotlib.pyplot as plt
# 그래프로 확인
sns.pairplot(df, hue='species');
plt.show()

3. 원-핫 인코딩
머신러닝이나 딥러닝을 수행할 때, 출력 데이터(Y)가 문자열(텍스트)로 구성된 경우 모델이 이를 처리할 수 있도록 숫자로 변환하는 과정이 필요하다. 특히, 다중 분류 문제에서는 각 클래스(레이블)를 0과 1로 이루어진 벡터 형태로 변환하는 원-핫 인코딩(One-Hot Encoding)을 사용한다.
현재 아이리스 데이터셋에서 품종(Species) 정보는 Iris-setosa, Iris-versicolor, Iris-virginica와 같이 문자열로 저장되어 있다.
딥러닝 모델은 문자열을 직접 다룰 수 없기 때문에 숫자로 변환하는 과정이 필요하다.
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
....
하지만 단순히 정수형 숫자로 변환(예: Setosa=1, Versicolor=2, Virginica=3)하면 모델이 숫자 간의 크기 관계를 학습할 가능성이 있다.
예를 들어, 모델이 Versicolor(2) > Setosa(1), Virginica(3) > Versicolor(2)와 같은 잘못된 관계를 학습할 수 있다.
이를 방지하기 위해 각 클래스별로 독립적인 벡터를 생성하여 변환하는 원-핫 인코딩을 적용한다.
# 데이터 분류
dataset = df.values
X = dataset[:,0:4].astype(float)
Y_obj = dataset[:,4]
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
Y_encoded = tf.keras.utils.to_categorical(Y)1. 주요 라이브러리
1.1. scikit-learn의 LabelEncoder
from sklearn.preprocessing import LabelEncoder- 문자열(텍스트) 데이터를 정수형 숫자로 변환하는 역할을 한다.
- 예를 들어, ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'] → [0, 1, 2]로 변환한다.
- 클래스 간 크기 관계가 포함되지 않도록 순서만 부여한다.
1.2. TensorFlow의 to_categorical
import tensorflow as tf- 정수형 숫자로 변환된 데이터를 0과 1로 이루어진 벡터 형태로 변환한다.
- 다중 분류 문제에서 softmax 출력층을 사용하기 위해 필수적인 과정이다.
2. 주요 함수의 개념
위 코드에서 원-핫 인코딩 과정에서 사용된 함수를 하나씩 살펴본다.
2.1. 데이터 준비
dataset = df.values
X = dataset[:,0:4].astype(float) # 입력값 (꽃잎 길이 등)
Y_obj = dataset[:,4] # 출력값 (품종)- 데이터셋을 넘파이 배열 형태로 변환 (df.values)
- X에는 입력 데이터 (꽃잎, 꽃받침의 길이와 너비) 저장
- Y_obj에는 품종 (Iris-setosa, Iris-versicolor, Iris-virginica) 저장
2.2. 문자열 데이터를 숫자로 변환 (Label Encoding)
e = LabelEncoder() # LabelEncoder 객체 생성
e.fit(Y_obj) # Y_obj 데이터 학습
Y = e.transform(Y_obj) # 문자열을 숫자로 변환- LabelEncoder()
- 문자열 데이터를 정수로 변환하기 위해 사용
- fit()을 이용해 문자열을 학습한 후, transform()을 통해 정수로 변환
- 변환 예시: ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'] → [0, 1, 2]
2.3. 정수 데이터를 원-핫 벡터로 변환 (One-Hot Encoding)
Y_encoded = tf.keras.utils.to_categorical(Y)- to_categorical()
- 정수 데이터를 0과 1로 이루어진 원-핫 벡터 형태로 변환
- 변환 예시: [0, 1, 2] → [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]]
4. 소프트맥스
다음으로는 모델을 만들어보자.
여기서 달라진 점이 있는데, 먼저 최종 출력 값이 3개 중 하나여야 하므로 출력층에 해당하는 Dense의 노트 수를 3으로 설정한다. 또한 활성화 함수로 앞서 나오지 않았던 소프트맥스(softmax)를 사용해 보겠다.
# 모델의 설정
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
소프트맥스 함수의 특징
소프트맥스 함수의 주요 특징은 다음과 같다.

1. 출력값의 총합이 항상 1이 되도록 변환
2. 각 클래스의 확률을 강조 : 가장 높은 확률을 가진 클래스는 더욱 두드러지게, 낮은 확률을 가진 클래스는 더 작아지도록 조정
3. 원-핫 인코딩 형태(예: [1, 0, 0])와 유사한 확률 분포 생성 : 이를 통해 정답 클래스를 효과적으로 분류할 수 있음
수식으로 표현하면 다음과 같다.

소프트맥스 함수의 동작 방식
소프트맥스 함수 : 주어진 점수를 합이 1인 확률로 변환한다!
소프트맥스 함수는 주어진 점수를 확률 형태로 변환한다. 예를 들어, 원래 점수가 다음과 같다고 가정한다.
| 클래스 | 점수 (logits) | 소프트맥스 변환 후 확률 |
| A | 2.0 | 0.665 |
| B | 1.0 | 0.244 |
| C | 0.1 | 0.090 |
이처럼 높은 점수를 가진 클래스는 더 큰 확률 값을 갖게 되고, 확률 값의 총합은 항상 1이 된다.
소프트맥스를 적용하면 최종적으로 정답 클래스의 확률이 가장 높아지고 나머지는 작아진다.
이 값이 교차 엔트로피 함수(categorical crossentropy)를 통해 0과 1로 가까워지면서 원-핫 인코딩 형태로 학습된다.
즉, 처음에는 확률값이 [0.6, 0.3, 0.1]처럼 나올 수 있으며 모델이 학습될수록 정답 확률이 높아지고, 결국 [1, 0, 0] 형태의 원-핫 벡터에 가까워진다. 이를 통해 다중 분류 문제에서 원하는 결과를 도출할 수 있다.
5. 아이리스 품종 예측 실행
# 데이터 분류
dataset = df.values
X = dataset[:,0:4].astype(float)
Y_obj = dataset[:,4]
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
Y_encoded = tf.keras.utils.to_categorical(Y)
# 모델의 설정
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
# 모델 컴파일
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 모델 실행
model.fit(X, Y_encoded, epochs=50, batch_size=1)
# 결과 출력
print("\n Accuracy: %.4f" % (model.evaluate(X, Y_encoded)[1]))이전의 이항 분류(binary classification)와 달리, 이번에는 세 가지 클래스 중 하나를 예측해야 한다.
따라서 적절한 오차 함수와 최적화 방법을 설정해야 한다.
- 오차 함수(loss function)
- categorical_crossentropy 사용
- 다중 분류 문제에 적합한 오차 함수
- 원-핫 인코딩된 정답 값과 모델이 예측한 확률 값 사이의 차이를 줄이는 역할
- 최적화 함수(optimizer)
- adam 사용
- 가중치를 효율적으로 조정하여 학습을 최적화
- adam은 학습 속도를 조정하는 기능이 있어, 별도의 하이퍼파라미터 조정 없이 좋은 성능을 낼 수 있음
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])- loss='categorical_crossentropy' → 다중 분류 문제에서 적합한 오차 함수
- optimizer='adam' → 학습 속도를 최적화하는 Adam 옵티마이저 사용
- metrics=['accuracy'] → 학습 과정에서 정확도를 모니터링
model.fit(X, Y_encoded, epochs=50, batch_size=1)
- epochs=50 → 데이터를 50번 반복하여 학습
- batch_size=1 → 한 번에 하나의 샘플을 학습
...
150/150
━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9472 - loss: 0.1108 5/5 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - accuracy: 0.9881 - loss: 0.0546
Accuracy: 0.9733
13장 과적합 피하기
1. 데이터의 확인과 실행
import pandas as pd
df = pd.read_csv('../dataset/sonar.csv', header=None)
print(df.info)
데이터셋의 샘플 수와 컬럼 수를 확인하는 것은 데이터 분석의 첫 단계이다. 총 208개의 샘플이 존재하며, 61개의 컬럼이 포함되어 있다.
이를 통해 60개의 속성(가로,0~59)과 1개의 클래스(가로,60)로 이루어져 있음을 짐작할 수 있다.
데이터를 구성하는 모든 컬럼이 실수형(float64)으로 되어 있지만, 맨 마지막 컬럼만 객체(object)형으로 되어 있는 것이 눈에 띈다.
이는 마지막 컬럼이 클래스(Label)일 가능성이 높으며, 머신러닝 모델을 학습하기 위해 데이터형 변환이 필요함을 의미한다.
<bound method DataFrame.info of 0 1 2 3 4 5 6 7 8 \
0 0.0200 0.0371 0.0428 0.0207 0.0954 0.0986 0.1539 0.1601 0.3109
1 0.0453 0.0523 0.0843 0.0689 0.1183 0.2583 0.2156 0.3481 0.3337
2 0.0262 0.0582 0.1099 0.1083 0.0974 0.2280 0.2431 0.3771 0.5598
3 0.0100 0.0171 0.0623 0.0205 0.0205 0.0368 0.1098 0.1276 0.0598
4 0.0762 0.0666 0.0481 0.0394 0.0590 0.0649 0.1209 0.2467 0.3564
.. ... ... ... ... ... ... ... ... ...
203 0.0187 0.0346 0.0168 0.0177 0.0393 0.1630 0.2028 0.1694 0.2328
204 0.0323 0.0101 0.0298 0.0564 0.0760 0.0958 0.0990 0.1018 0.1030
205 0.0522 0.0437 0.0180 0.0292 0.0351 0.1171 0.1257 0.1178 0.1258
206 0.0303 0.0353 0.0490 0.0608 0.0167 0.1354 0.1465 0.1123 0.1945
207 0.0260 0.0363 0.0136 0.0272 0.0214 0.0338 0.0655 0.1400 0.1843
9 ... 51 52 53 54 55 56 57 \
0 0.2111 ... 0.0027 0.0065 0.0159 0.0072 0.0167 0.0180 0.0084
1 0.2872 ... 0.0084 0.0089 0.0048 0.0094 0.0191 0.0140 0.0049
2 0.6194 ... 0.0232 0.0166 0.0095 0.0180 0.0244 0.0316 0.0164
3 0.1264 ... 0.0121 0.0036 0.0150 0.0085 0.0073 0.0050 0.0044
4 0.4459 ... 0.0031 0.0054 0.0105 0.0110 0.0015 0.0072 0.0048
.. ... ... ... ... ... ... ... ... ...
203 0.2684 ... 0.0116 0.0098 0.0199 0.0033 0.0101 0.0065 0.0115
204 0.2154 ... 0.0061 0.0093 0.0135 0.0063 0.0063 0.0034 0.0032
205 0.2529 ... 0.0160 0.0029 0.0051 0.0062 0.0089 0.0140 0.0138
206 0.2354 ... 0.0086 0.0046 0.0126 0.0036 0.0035 0.0034 0.0079
207 0.2354 ... 0.0146 0.0129 0.0047 0.0039 0.0061 0.0040 0.0036
58 59 60
0 0.0090 0.0032 R
1 0.0052 0.0044 R
2 0.0095 0.0078 R
3 0.0040 0.0117 R
4 0.0107 0.0094 R
.. ... ... ..
203 0.0193 0.0157 M
204 0.0062 0.0067 M
205 0.0077 0.0031 M
206 0.0036 0.0048 M
207 0.0061 0.0115 M
[208 rows x 61 columns]>
실제로 일부를 출력하면 다음과 같다:
0 1 2 3 4 5 6 7 8 \
0 0.0200 0.0371 0.0428 0.0207 0.0954 0.0986 0.1539 0.1601 0.3109
1 0.0453 0.0523 0.0843 0.0689 0.1183 0.2583 0.2156 0.3481 0.3337
2 0.0262 0.0582 0.1099 0.1083 0.0974 0.2280 0.2431 0.3771 0.5598
3 0.0100 0.0171 0.0623 0.0205 0.0205 0.0368 0.1098 0.1276 0.0598
4 0.0762 0.0666 0.0481 0.0394 0.0590 0.0649 0.1209 0.2467 0.3564
9 ... 51 52 53 54 55 56 57 \
0 0.2111 ... 0.0027 0.0065 0.0159 0.0072 0.0167 0.0180 0.0084
1 0.2872 ... 0.0084 0.0089 0.0048 0.0094 0.0191 0.0140 0.0049
2 0.6194 ... 0.0232 0.0166 0.0095 0.0180 0.0244 0.0316 0.0164
3 0.1264 ... 0.0121 0.0036 0.0150 0.0085 0.0073 0.0050 0.0044
4 0.4459 ... 0.0031 0.0054 0.0105 0.0110 0.0015 0.0072 0.0048
58 59 60
0 0.0090 0.0032 R
1 0.0052 0.0044 R
2 0.0095 0.0078 R
3 0.0040 0.0117 R
4 0.0107 0.0094 R
[5 rows x 61 columns]
이제 모델을 실행해보자. 다만, 저서의 코드와는 조금 수정할 점이 있다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import numpy
import tensorflow as tf
# seed 값 설정
numpy.random.seed(3)
tf.random.set_seed(3)
# 데이터 입력
df = pd.read_csv('../dataset/sonar.csv', header=None)
# 데이터셋을 numpy 배열로 변환
dataset = df.values
X = dataset[:, 0:60].astype(float) # 입력 데이터 (실수형 변환)
Y_obj = dataset[:, 60] # 출력 데이터 (클래스)
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj) # R과 M을 0과 1로 변환
# 모델 설정
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu')) # 첫 번째 은닉층
model.add(Dense(10, activation='relu')) # 두 번째 은닉층
model.add(Dense(1, activation='sigmoid')) # 출력층 (이진 분류이므로 sigmoid 사용)
# 모델 컴파일 (이진 분류 문제이므로 binary_crossentropy 사용)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 모델 실행
model.fit(X, Y, epochs=200, batch_size=5)
# 결과 출력
accuracy = model.evaluate(X, Y)[1]
print("\n Accuracy: %.4f" % accuracy)수정 사항
- from keras.layers.core import Dense → from keras.layers import Dense
- Dense가 keras.layers 내부로 통합되었기 때문에 이를 변경해야 한다.
- keras 대신 tensorflow.keras 사용 추천
- Keras는 TensorFlow 2.0 이후 tensorflow.keras로 통합되었기 때문에 **from tensorflow.keras.layers import Dense**로 변경하는 것이 더 안정적이다.
- 손실 함수 수정
- mean_squared_error는 이진 분류 문제에서는 적절하지 않다.
- binary_crossentropy로 변경해야 한다.
이 모델의 정확도는 100%로 나온다. 정말로 100% 정확도의 모델이 만들어진것인가? 다음 장을 확인하자.
2. 과적합 이해하기
과적합(overfitting)이란 머신러닝과 딥러닝 모델이 훈련 데이터에는 높은 성능을 보이지만, 새로운 데이터에서는 일반화되지 못하는 현상을 의미한다. 쉽게 말해, 훈련 데이터에 너무 과하게 맞춰져 있어 새로운 데이터를 처리하는 능력이 떨어지는 것이다.
훈련데이터에 너무 과하게 맞춰져, 테스트 데이터(훈련되지 않는 새로운 데이터)를 처리하는 능력이 떨어지는 현상.
과적합을 이해하려면 학습 과정에서 모델이 데이터를 어떻게 분석하는지 생각해 볼 필요가 있다. 모델이 학습 데이터의 패턴을 잘 파악하는 것은 중요하지만, 훈련 데이터에 지나치게 의존하여 세부적인 노이즈까지 학습하면 오히려 성능이 저하될 수 있다. 이를 "데이터를 너무 외우는 현상"이라고 표현하기도 한다.
과적합의 대표적인 예로, 특정 시험 문제만 반복해서 공부한 학생을 떠올릴 수 있다. 이 학생은 시험 문제를 정확하게 외우고 있어서 같은 문제가 나오면 높은 점수를 받을 수 있지만, 시험 문제가 조금만 바뀌어도 제대로 풀지 못하는 경우가 많다. 딥러닝 모델도 이와 비슷하게, 훈련 데이터에만 최적화되어 있을 경우 실제 새로운 데이터에서는 제대로 동작하지 않을 수 있다.
과적합의 원인
과적합이 발생하는 이유는 여러 가지가 있다.
- 훈련 데이터의 양이 부족한 경우: 모델이 충분한 데이터를 학습하지 못하면, 특정한 패턴을 과하게 학습할 가능성이 커진다.
- 모델이 너무 복잡한 경우: 층(layer)과 노드(node)가 많아지면 모델이 데이터를 지나치게 세밀하게 분석할 수 있다. 이로 인해 불필요한 패턴까지 학습하게 되어 새로운 데이터에 일반화되지 않는다.
- 테스트 데이터와 학습 데이터가 비슷한 경우: 모델이 훈련 데이터를 기반으로 평가되었지만, 실제 적용 환경에서는 다른 데이터가 주어질 수 있다. 훈련 데이터와 테스트 데이터가 지나치게 비슷하면, 모델이 실전에서 좋은 성능을 보장하지 못할 수도 있다.
과적합의 시각적 이해
과적합을 그래프로 표현하면 더 쉽게 이해할 수 있다. 아래 그림을 생각해보자.
과적합 문제를 해결하기 위해서는 여러 가지 방법을 적용할 수 있다. 다음 단계에서 과적합을 방지하는 대표적인 해결 방법에 대해 살펴보겠다.

- 과소적합(underfitting): 모델이 너무 단순하여 데이터를 잘 설명하지 못하는 경우.
- 적절한 학습(optimal fit): 모델이 데이터를 잘 일반화하여 새로운 데이터에도 높은 성능을 보이는 경우.
- 과적합(overfitting): 모델이 훈련 데이터에 너무 최적화되어 있으며, 새로운 데이터에는 제대로 적용되지 않는 경우. 이 경우 모델이 불필요한 노이즈까지 학습하게 된다.
3. 학습셋과 데이터셋
과적합을 방지하는 한 가지 방법은 훈련 데이터와 평가 데이터를 명확히 구분하는 것이다. 학습을 진행할 때 훈련 데이터만 사용하고, 모델이 실제로 얼마나 잘 작동하는지는 테스트 데이터를 사용해 확인해야 한다.
| 학습 진행 | 작동 확인 | |
| 학습 데이터 (70%) | 테스트 데이터 (30%) | |
학습셋과 테스트셋의 분리
예를 들어, 전체 데이터셋이 100개의 샘플로 이루어져 있다고 가정하자. 이 데이터 중 70개를 학습셋(training set)으로 사용하고, 나머지 30개를 테스트셋(test set)으로 사용하면 다음과 같은 과정이 이루어진다.
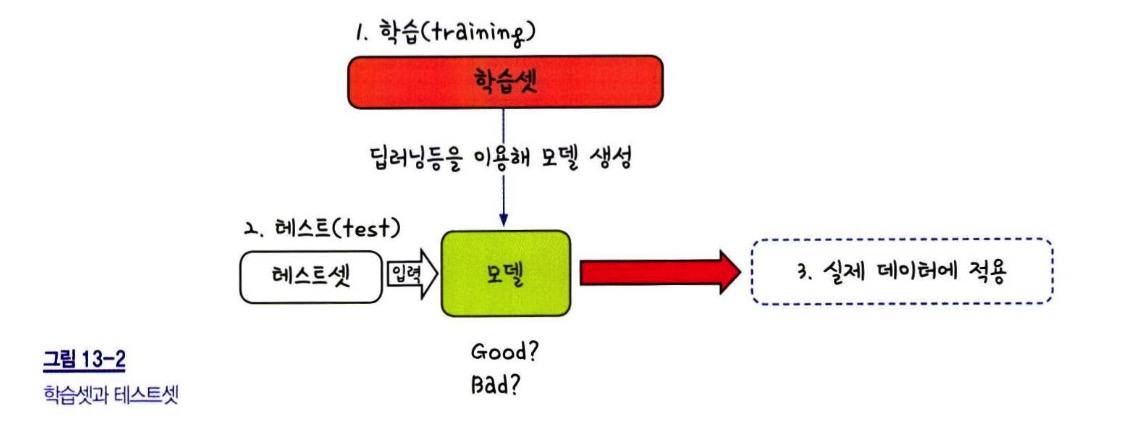
• 학습 단계 : 신경망을 설계하고, 학습 데이터(70개 샘플)를 이용하여 가중치와 편향을 최적화 / 학습된 모델을 저장
• 테스트 단계 : 테스트셋(30개 샘플)에 적용하여 예측 성능을 평가 / 새로운 데이터를 얼마나 잘 예측하는지 확인
이러한 과정을 통해 훈련 데이터에 과적합된 모델인지, 새로운 데이터에도 잘 일반화된 모델인지 판단할 수 있다.
학습셋만으로 평가했을 때의 문제점
지금까지 우리가 실행한 코드에서는 테스트셋을 따로 만들지 않고 학습을 진행했음에도 불구하고 정확도(Accuracy)를 계산할 수 있었다.
이것은 우리가 훈련 데이터 자체를 사용하여 모델의 성능을 측정했기 때문이다. 하지만 머신러닝의 목표는 새로운 데이터를 예측하는 것이므로, 훈련 데이터에서 높은 성능을 보였다고 해서 실제 새로운 데이터에서도 좋은 결과가 나오는 것은 아니다.
즉, 학습셋만으로 평가할 경우 다음과 같은 문제가 발생할 수 있다.
- 층을 추가하거나 에포크(epoch)를 늘릴수록 학습셋에서의 정확도는 계속 증가한다.
- 그러나 테스트셋에서는 오히려 성능이 떨어지는 현상이 발생할 수 있다.
- 이는 모델이 학습 데이터에 너무 최적화되어 일반적인 패턴을 학습하는 것이 아니라, 특정 샘플의 특성을 지나치게 외운(overfitting) 상태가 되었기 때문이다.
학습을 진행해도 테스트 결과가 더 이상 좋아지지 않는 지점에서 학습을 멈춰야 한다. 이때의 학습 정도가 가장 적절하다.
은닉층 수와 예측률 변화
과적합이 실제로 어떻게 발생하는지 이해하기 위해, 은닉층(hidden layer)의 개수에 따라 학습셋과 테스트셋의 예측률이 어떻게 변하는지를 살펴보자. 다음 표는 세즈노프스키 교수가 연구한 결과를 바탕으로 작성된 것이다.

| 은닉층 수의 변화 | 학습셋의 예측률 (%) | 테스트셋의 예측률 (%) |
| 0 | 79.3 | 73.1 |
| 2 | 96.2 | 85.7 |
| 3 | 98.1 | 87.6 |
| 6 | 99.4 | 89.3 |
| 12 | 99.8 | 90.4 |
| 24 | 100 | 89.2 |
이 표에서 중요한 부분은 은닉층의 개수가 증가할수록 학습셋에서의 예측률은 계속 증가하지만, 테스트셋에서는 일정 수준을 넘어서면 오히려 성능이 떨어진다는 점이다.
✔ 은닉층이 12개일 때 테스트셋에서의 정확도가 최고(90.4%)를 기록했다.
✔ 하지만 24개로 증가하자 학습셋의 정확도는 100%로 완벽해졌지만, 테스트셋의 정확도는 오히려 감소(89.2%)했다.
이러한 결과는 층이 많을수록 모델이 학습 데이터에 너무 최적화되어 새로운 데이터에 대한 일반화 능력이 떨어진다는 것을 의미한다.
학습셋과 테스트셋을 나누는 방법
과적합을 방지하기 위해서는 훈련 데이터와 테스트 데이터를 미리 분리하여 학습을 진행하는 것이 중요하다.
이를 위해 scikit-learn의 train_test_split() 함수를 사용할 수 있다. 일반적으로 70%를 학습 데이터, 30%를 테스트 데이터로 설정하며, 코드는 다음과 같이 작성할 수 있다.
# 학습 셋과 테스트 셋의 구분 (train 70%, test 30%)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)
- X : 입력 데이터(특징 데이터)
- Y : 출력 데이터(정답 라벨)
- test_size=0.3 : 전체 데이터셋에서 30%를 테스트셋(test set)으로 사용, 나머지 70%를 학습셋(train set)으로 사용
- random_state=seed :
- 데이터셋을 나눌 때 랜덤성이 개입되므로, 실행할 때마다 동일한 결과를 얻기 위해 random_state 값을 고정하는 역할을 한다.
- 동일한 random_state 값을 사용하면 항상 같은 학습셋과 테스트셋으로 분리된다.
과적합을 방지하는 방법에는 학습 데이터 양을 늘리는 것, 정규화(regularization)를 적용하는 것, 드롭아웃(dropout)을 사용하는 것 등 다양한 기법이 존재한다. 다음 단계에서는 과적합을 방지하는 대표적인 기법들을 자세히 살펴보겠다.
전체 코드는 다음과 같다:
import numpy
import tensorflow as tf
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# seed 값 설정
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(3)
# 데이터 불러오기
df = pd.read_csv('../dataset/sonar.csv', header=None)
'''
print(df.info())
print(df.head())
'''
dataset = df.values
X = dataset[:,0:60].astype(numpy.float32) # float32로 변환
Y_obj = dataset[:,60]
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj).astype(numpy.float32) # float32로 변환
# 학습 셋과 테스트 셋의 구분 (train 70%, test 30%)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)
# 모델 구성
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])
# 모델 학습
model.fit(X_train, Y_train, epochs=130, batch_size=5)
# 테스트셋에 모델 적용
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))...
29/29
━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step - accuracy: 1.0000 - loss: 0.0023 2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 96ms/step - accuracy: 0.8419 - loss: 0.1396
Test Accuracy: 0.8254
4. 모델 저장과 재사용
딥러닝 모델을 학습한 후 만족스러운 결과를 얻었다면, 이를 저장하여 나중에 다시 불러와 새로운 데이터에 사용할 수 있다. 매번 모델을 학습시키는 것은 시간이 오래 걸리므로, 한 번 학습한 모델을 저장하고 재사용하는 과정은 매우 중요하다.
1. 모델 저장하기
모델을 저장하는 방법은 model.save() 함수를 사용하는 것이다.
model.save('my_model.h5')
여기서 'my_model.h5'는 저장될 파일의 이름으로, .h5 확장자는 HDF5(데이터 저장 포맷) 형식을 의미한다.
이 코드를 실행하면, 학습된 모델의 구조와 가중치, 옵티마이저 상태 등이 함께 저장된다.
2. 모델 삭제 및 불러오기
모델을 저장한 후, 메모리에서 삭제한 후 다시 불러오는 과정도 확인할 수 있다.
하지만, load_model을 사용하려면 반드시 keras.models에서 import해야 한다. 모델을 저장하고 불러올 때는 같은 환경에서 실행해야 한다. 즉, keras의 버전이 다르면 문제가 발생할 수 있다. load_model을 실행하기 전에 모델이 올바르게 저장되었는지 확인하려면 아래와 같이 .h5 파일이 생성되었는지 확인한다.
del model # 현재 모델을 메모리에서 삭제 model = load_model('my_model.h5') # 저장된 모델을 불러오기
#del model : 현재 메모리에 로드된 모델을 삭제한다.
#load_model('my_model.h5') : 저장된 모델을 다시 불러온다.
이렇게 하면 학습된 모델을 불러와 추가 학습을 하거나 새로운 데이터로 테스트할 수 있다.
import numpy
import tensorflow as tf
import pandas as pd
from keras.models import Sequential, load_model # load_model 추가
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# seed 값 설정
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(3)
# 데이터 불러오기
df = pd.read_csv('../dataset/sonar.csv', header=None)
'''
print(df.info())
print(df.head())
'''
dataset = df.values
X = dataset[:,0:60].astype(numpy.float32) # float32로 변환
Y_obj = dataset[:,60]
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj).astype(numpy.float32) # float32로 변환
# 학습 셋과 테스트 셋의 구분 (train 70%, test 30%)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)
# 모델 구성
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])
# 모델 학습
model.fit(X_train, Y_train, epochs=130, batch_size=5)
# 테스트셋에 모델 적용
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))
# 모델 저장
model.save('my_model.h5')
# 현재 모델 삭제
del model
# 저장된 모델 불러오기
model = load_model('my_model.h5') # 오류 해결된 부분
# 불러온 모델로 테스트셋 평가
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))5. k겹 교차 검증
모델의 성능을 평가할 때 중요한 요소 중 하나는 데이터의 충분한 활용과 일반화 성능이다. 특히, 데이터가 부족한 경우 모델의 학습과 평가를 균형 있게 수행하기 어려워진다. 일반적으로 학습을 진행할 때 데이터를 학습셋과 테스트셋으로 나누는데, 이때 학습셋이 너무 많으면 테스트셋이 부족해지고, 테스트셋이 너무 많으면 학습이 충분히 이루어지지 않는 문제가 발생할 수 있다.
이를 해결하기 위한 방법 중 하나가 k겹 교차 검증(k-Fold Cross Validation)이다. 이 방법은 데이터를 k개의 그룹으로 나누어, 한 개의 그룹을 테스트셋으로 사용하고 나머지를 학습셋으로 활용하는 방식을 반복하여 모델을 평가하는 방법이다.
k겹 교차 검증의 원리
k겹 교차 검증은 다음과 같은 방식으로 진행된다.
- 전체 데이터셋을 k개의 폴드(fold)로 나눈다.
- k번 반복하며 각 반복마다 한 개의 폴드를 테스트셋으로 사용하고 나머지를 학습셋으로 활용한다.
- k번의 평가 결과를 평균 내어 모델의 최종 성능을 측정한다.
예를 들어, 5겹 교차 검증(5-Fold Cross Validation)을 진행하면 데이터셋을 5개의 그룹으로 나누고, 다음과 같은 방식으로 진행된다.

1. 첫 번째 폴드를 테스트셋으로 사용하고 나머지 4개 폴드를 학습셋으로 사용하여 모델을 훈련한다.
2. 두 번째 폴드를 테스트셋으로 사용하고 나머지 4개 폴드를 학습셋으로 사용하여 모델을 훈련한다.
3. 이 과정을 마지막 폴드까지 반복한다.
4. 5개의 평가 결과를 평균 내어 최종 모델 성능을 결정한다.
이러한 과정은 데이터의 모든 부분이 한 번씩 테스트셋으로 활용되도록 하여 모델 평가의 신뢰도를 높여준다.
Stratified K-Fold 적용하기
딥러닝 모델에서 k겹 교차 검증을 적용하려면 scikit-learn의 StratifiedKFold를 활용할 수 있다. 이 방법은 데이터의 클래스 비율을 유지하면서 폴드를 나누는 기능을 제공한다.
from sklearn.model_selection import StratifiedKFold
# k겹 교차 검증을 위한 설정
n_fold = 10 # 10겹 교차 검증
skf = StratifiedKFold(n_splits=n_fold, shuffle=True, random_state=seed)위 코드에서 n_splits=10은 데이터를 10개의 폴드로 나누겠다는 의미이다. shuffle=True는 데이터를 무작위로 섞어 폴드를 나누도록 설정하며, random_state=seed를 지정하면 동일한 결과를 재현할 수 있다.
모델을 학습할 때, for 반복문을 활용하여 각 폴드에 대해 모델을 학습시키고 평가할 수 있다.
또한 정확도를 매변 저장하여 한 번에 보여줄 수 있게 accuracy 배열을 만든다. 하지만 최신 버전에 맞춰 조금 수정할 필요가 있다.
from keras.models import Sequential
from keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
import numpy as np
import pandas as pd
import tensorflow as tf
# seed 값 설정
seed = 0
np.random.seed(seed)
tf.random.set_seed(3)
# 데이터 불러오기
df = pd.read_csv('../dataset/sonar.csv', header=None)
# 데이터셋 분리
dataset = df.values
X = dataset[:, 0:60].astype(np.float32) # X 데이터를 float32로 변환
Y_obj = dataset[:, 60]
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
# 10개 fold로 분할
n_fold = 10
skf = StratifiedKFold(n_splits=n_fold, shuffle=True, random_state=seed)
# 정확도 저장용 리스트
accuracy = []
# 모델 학습 및 평가
for train_idx, test_idx in skf.split(X, Y):
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])
# 데이터를 float32로 변환하여 numpy 배열로 인덱싱
X_train, X_test = X[train_idx].astype(np.float32), X[test_idx].astype(np.float32)
Y_train, Y_test = Y[train_idx].astype(np.float32), Y[test_idx].astype(np.float32)
# 모델 학습
model.fit(X_train, Y_train, epochs=100, batch_size=5, verbose=0)
# 모델 평가
k_accuracy = "%.4f" % (model.evaluate(X_test, Y_test, verbose=0)[1])
accuracy.append(k_accuracy)
# 최종 k겹 교차 검증 결과 출력
print("\n %d-fold cross validation accuracy:" % n_fold, accuracy)
1. 데이터 타입 변환
X 데이터를 float32로 변환하여 TensorFlow가 처리할 수 있도록 함 : X = dataset[:, 0:60].astype(np.float32)
Y 데이터도 float32로 변환하여 TensorFlow에서 처리 가능하도록 조정 : Y = e.transform(Y_obj).astype(np.float32)
2. 데이터 인덱싱 방식 변경
기존에는 train과 test 인덱스를 X[train], Y[train] 형태로 사용했으나, 이 방식은 리스트로 변환될 가능성이 있어 명확한 numpy.ndarray 인덱싱 방식으로 수정
X_train, X_test = X[train_idx].astype(np.float32), X[test_idx].astype(np.float32)
Y_train, Y_test = Y[train_idx].astype(np.float32), Y[test_idx].astype(np.float32)3. 모델 학습 시 verbose=0 추가
모델 학습 과정에서 불필요한 출력을 줄이고, 실행 속도를 높이기 위해 verbose=0을 설정
model.fit(X_train, Y_train, epochs=100, batch_size=5, verbose=0)1. 라이브러리 불러오기
from keras.models import Sequential
from keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
import numpy as np
import pandas as pd
import tensorflow as tf- keras.models.Sequential : 신경망 모델을 순차적으로 정의하는 데 사용되는 API.
- keras.layers.Dense : 완전 연결층(Fully Connected Layer)을 추가하는 함수.
- sklearn.preprocessing.LabelEncoder : 문자열 데이터를 숫자로 변환하는 데 사용.
- sklearn.model_selection.StratifiedKFold : K겹 교차 검증을 수행하는 함수.
- numpy : 배열 연산을 수행하는 라이브러리.
- pandas : CSV 파일을 읽고 데이터프레임을 다루는 라이브러리.
- tensorflow : 딥러닝 모델을 학습시키는 주요 프레임워크.
2. Seed 값 설정
재현 가능한 실험을 위해 랜덤 시드(seed)를 고정하여 동일한 결과가 나오도록 설정한다.
seed = 0
np.random.seed(seed)
tf.random.set_seed(3)3. 데이터 불러오기
df = pd.read_csv('../dataset/sonar.csv', header=None)
# pandas 라이브러리의 read_csv() 함수를 이용해 데이터를 불러온다.
# header=None : 데이터 파일에 컬럼명이 없다는 것을 의4. 데이터 전처리
dataset = df.values
X = dataset[:, 0:60].astype(np.float32) # X 데이터를 float32로 변환
Y_obj = dataset[:, 60]
- 데이터셋을 넘파이 배열(numpy.ndarray) 형태로 변환.
- 입력 데이터(X) : 첫 번째부터 60번째 컬럼까지 사용.
- 출력 데이터(Y_obj) : 마지막 61번째 컬럼에 해당.
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
- LabelEncoder()를 사용하여 출력 데이터(Y)가 문자열인 경우, 이를 숫자로 변환.
- 예를 들어 ['M', 'M', 'R', 'R'] 같은 문자열 데이터를 [1, 1, 0, 0]으로 변환.
5. K겹 교차 검증 설정
n_fold = 10
skf = StratifiedKFold(n_splits=n_fold, shuffle=True, random_state=seed)
- Stratified K-Fold : 데이터의 클래스 분포를 유지하면서 K개의 폴드로 나누는 방식.
- n_splits=10 → 데이터를 10개 그룹으로 나눈 후 10번 학습을 수행.
- shuffle=True → 데이터를 섞어서 좀 더 균등하게 분할.
- random_state=seed → 결과의 일관성을 유지하기 위해 시드값을 설정.
6. 모델 학습 및 평가
accuracy = [] # 각 폴드(fold)의 정확도(accuracy)를 저장할 리스트.
for train_idx, test_idx in skf.split(X, Y):
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
- for 루프를 사용하여 각 폴드별로 모델을 학습.
- Sequential 모델을 생성한 후 3개의 Dense Layer(완전 연결층) 추가.
- 첫 번째 은닉층 : 노드 24개, relu 활성화 함수.
- 두 번째 은닉층 : 노드 10개, relu 활성화 함수.
- 출력층 : 노드 1개, sigmoid 활성화 함수(이진 분류 문제이므로 사용).
model.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])
- 오차 함수(loss) : mean_squared_error (MSE, 평균 제곱 오차) 사용(보통 회귀 문제에서 사용, 이진 분류서 일부 적용 가능)
- 최적화 함수(optimizer) : adam 사용. 적응형 학습률을 가지며 대부분의 딥러닝 문제에서 성능이 좋음.
- 평가지표(metrics) : accuracy (정확도) 사용.
X_train, X_test = X[train_idx].astype(np.float32), X[test_idx].astype(np.float32)
Y_train, Y_test = Y[train_idx].astype(np.float32), Y[test_idx].astype(np.float32)
- 훈련셋과 테스트셋을 넘파이 배열(numpy.ndarray)로 변환하고 데이터 타입을 float32로 설정.
- astype(np.float32) : TensorFlow가 기대하는 자료형을 맞추기 위해 필요.
model.fit(X_train, Y_train, epochs=100, batch_size=5, verbose=0)
모델 학습(fit())
- epochs=100 → 전체 데이터셋을 100번 반복 학습.
- batch_size=5 → 한 번에 5개 샘플씩 가중치 업데이트.
- verbose=0 → 학습 과정의 출력(log)을 생략하여 깔끔한 결과 확인.
k_accuracy = "%.4f" % (model.evaluate(X_test, Y_test, verbose=0)[1])
accuracy.append(k_accuracy)
모델 평가(evaluate())
- X_test, Y_test를 사용하여 테스트셋의 성능을 평가
- 정확도를 %.4f 형식으로 저장하여 accuracy 리스트에 추가.
'Python > [모두의 딥러닝]' 카테고리의 다른 글
| [모두의 딥러닝] #3. 신경망의 이해 (0) | 2025.03.05 |
|---|---|
| [모두의 딥러닝] #2. 딥러닝의 동작원리 (2) | 2025.01.03 |
| [모두의 딥러닝] #1. 딥러닝 시작을 위한 준비 운동 (2) | 2024.12.26 |
| [모두의 딥러닝] #2. 딥러닝의 동작 원리 (0) | 2024.08.13 |
| [모두의 딥러닝] #1. 딥러닝 시작을 위한 준비 운동 (1) | 2024.07.18 |



