스테레오 카메라 알고리즘 제작 | Notion
#1. CNN 이용 Depth Map 구현
udangtangtang-cording-oldcast1e.notion.site
프로젝트 목표
라이다 센서 개요
라이다(LiDAR, Light Detection and Ranging) 센서는 레이저를 이용해 주변 환경의 거리 및 형상 정보를 정밀하게 측정하는 장치입니다. 라이다는 레이저 펄스를 발사하고, 대상물에 반사된 신호가 다시 돌아오는 시간을 측정하여 거리 정보를 얻습니다.
라이다 센서는 자율 주행차, 드론, 로봇 공학 등에서 널리 사용되며, 특히 주변 물체와의 거리 및 위치를 정확하게 파악해야 하는 응용 분야에서 중요한 역할을 합니다. 주변 조명 조건에 거의 영향을 받지 않기 때문에 야간이나 악천후 환경에서도 안정적인 성능을 발휘할 수 있습니다. 그러나 상대적으로 고가이며, 전력 소비가 크고 데이터 처리에 많은 자원이 필요하다는 단점이 있습니다.
스테레오 비전 개요
스테레오 비전(stereo vision) 시스템은 두 개의 카메라를 사용해 물체의 깊이와 3차원 구조를 파악하는 기술입니다. 두 카메라는 서로 다른 위치에서 촬영된 이미지를 통해 인간의 두 눈이 사물을 입체적으로 인식하는 것과 유사한 방식으로 깊이 정보를 추출합니다.
스테레오 비전은 물체의 색상과 텍스처를 포함한 풍부한 시각적 정보를 제공하며, 이를 통해 객체 인식, 분류, 거리 측정 등 다양한 작업을 수행할 수 있습니다. 특히 자율 주행차, 로봇, 드론 등에서 널리 사용되며, 낮이나 밝은 환경에서 높은 성능을 발휘합니다.
스테레오 비전의 주요 장점은 라이다에 비해 비용이 낮고, 전력 소비가 적으며, 설치가 용이하다는 점입니다. 다만, 조명 조건에 민감하여 야간이나 강한 빛이 있는 환경에서는 성능이 저하될 수 있습니다. 스테레오 비전은 라이다와 상호 보완적인 기술로, 색상 및 텍스처 인식이 필요한 상황에서 특히 유리합니다.
| 비용 | 저렴함 | 상대적으로 고가 |
| 색상 및 텍스처 정보 | 색상 및 텍스처 정보 제공 | 거리 및 형상 정보만 제공 |
| 데이터 처리 용이성 | 사람의 시각과 유사하여 이해하기 쉬움 | 점군 데이터를 처리하는 데 추가적인 알고리즘 필요 |
| 전력 소비 | 전력 소비가 적음 | 전력 소비가 높음 |
| 크기 및 설치 용이성 | 작고 설치가 용이함 | 크고 무거워 설치에 제약이 있을 수 있음 |
| 조명 조건에 대한 내성 | 조명 조건에 따라 성능 변동 가능 | 주변 조명에 영향을 받지 않음 |
| 활용 분야 | 색상 및 텍스처가 중요한 객체 인식 | 거리와 형상 측정에 유리 |
프로젝트 목표
시중에서 가장 저렴한 가격으로 자율 주행에 접목 가능한 스테레오 비전을 구현해 보자!
#1. CNN 이용 Depth Map 구현
CNN(Convolutional Neural Network)은 딥러닝에서 주로 이미지 처리와 관련된 작업에 사용되는 신경망 구조입니다. CNN은 이미지 분류, 객체 인식, 영상 분석 등 다양한 시각적 데이터를 처리하는 데 뛰어난 성능을 발휘합니다.
CNN의 핵심 구성 요소는 합성곱층(Convolutional Layer)으로, 입력 이미지에서 특징을 추출하는 역할을 합니다. 합성곱층은 필터(커널)를 사용해 이미지의 작은 영역을 스캔하면서 특징 맵(feature map)을 생성합니다. 이 과정에서 이미지의 주요 특징(예: 가장자리, 텍스처 등)이 강조됩니다.
• 합성곱층(Convolutional Layer): 이미지에서 지역적인 특징을 추출합니다.
• 풀링층(Pooling Layer): 특징 맵의 크기를 줄여 계산량을 줄이고, 중요한 특징을 강조합니다.
• 완전 연결층(Fully Connected Layer): 추출된 특징을 바탕으로 최종 예측을 수행합니다.
CNNv1
스테레오 비전을 구현하기 위해 CNN 알고리즘을 사용하여 두 개의 카메라로 촬영한 이미지를 기반으로 Depth map을 생성하고 화면에 출력하는 프로그램 작성.
1. 기준 영상(좌측 이미지)과 목표 영상(우측 이미지)의 시차 탐색 범위 내 모든 픽셀에 윈도우 설정.
2. 좌측 윈도우와 우측 시차 탐색 범위 내 윈도우들 간의 정합 비용(비유사도) 추정.
3. 계산된 정합 비용들을 그래프로 나타내고, 가장 작은 정합 비용을 가지는 시차 선택.
4. y축이 다른 경우 렉티피케이션(rectification) 과정을 통해 좌/우 영상의 y축을 일치시킴.
이미지 경로:
왼쪽 이미지: /Users/apple/Desktop/Python/Smarcle/MakersDay/StereoCam/SAD/사진자료/left.jpg
오른쪽 이미지: /Users/apple/Desktop/Python/Smarcle/MakersDay/StereoCam/SAD/사진자료/right.jpg
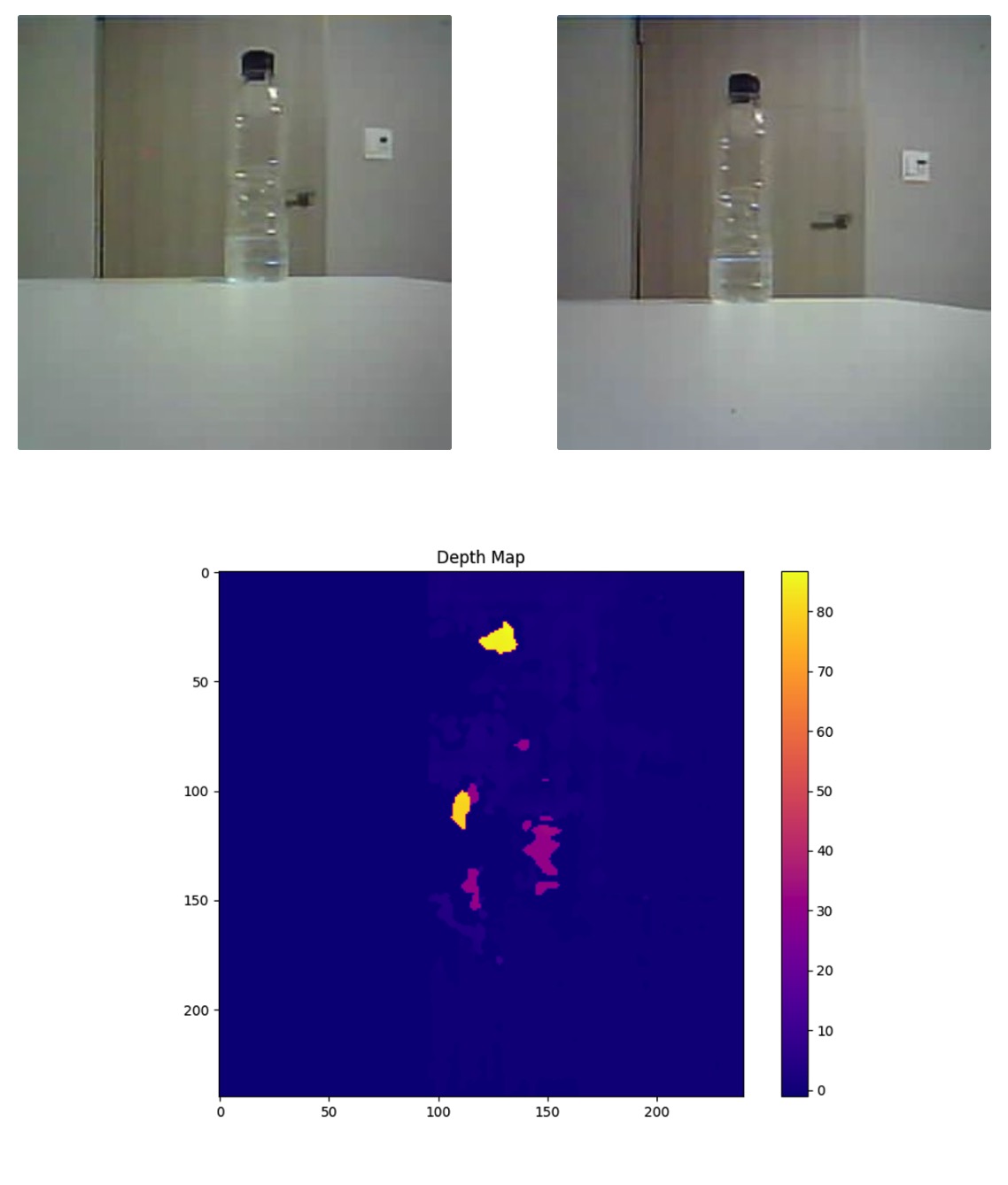
CNNv2: Census Transform
ESP32 CAM을 사용하여 스테레오 비전을 구현하고, Census Transform 알고리즘을 이용한 영역 기반 정합 방법을 사용하여 Depth map을 생성하고 출력하는 프로그램을 작성 및 카메라와 물체 간의 추정 거리를 터미널에 출력하는 것이 목표.
1. 기준 영상(좌측 이미지)과 목표 영상(우측 이미지)의 시차 탐색 범위 내 모든 픽셀에 윈도우 설정.
2. 좌측 윈도우와 우측 시차 탐색 범위 내 윈도우들 간의 정합 비용(비유사도) 추정 (Census Transform 알고리즘 사용).
3. 계산된 정합 비용들을 그래프로 나타내고, 가장 작은 정합 비용을 가지는 시차 선택.
4. y축이 다른 경우 렉티피케이션(rectification) 과정을 통해 좌/우 영상의 y축을 일치시킴.
| 상수 | 초점 거리 | fl = 2.043636363636363 |
| tan(세타) | antheta = 0.7648732789907391 |
왼쪽 이미지: /Users/apple/Desktop/Python/Smarcle/MakersDay/StereoCam/SAD/사진자료/left.jpg
오른쪽 이미지: /Users/apple/Desktop/Python/Smarcle/MakersDay/StereoCam/SAD/사진자료/right.jpg
• Depth map 화면에 출력
• 카메라와 물체 간의 추정 거리 터미널에 출력
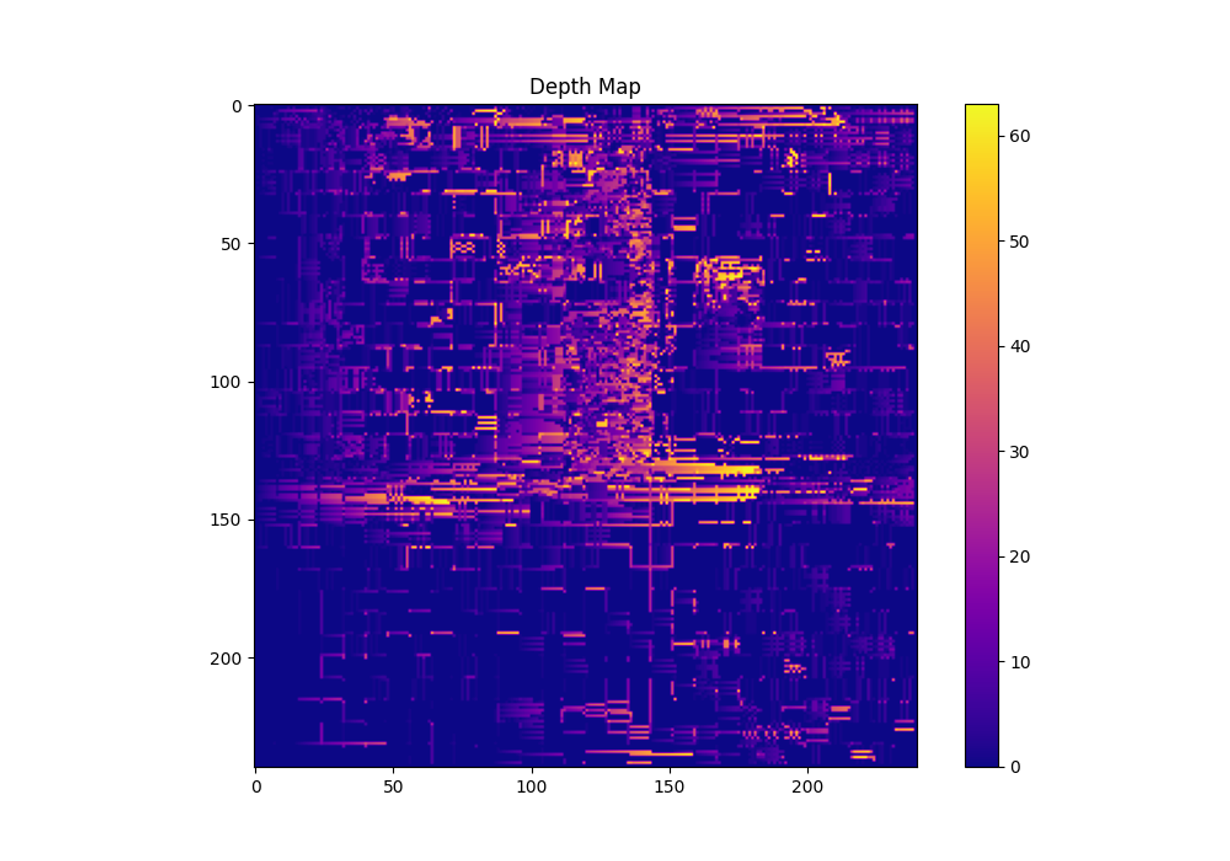
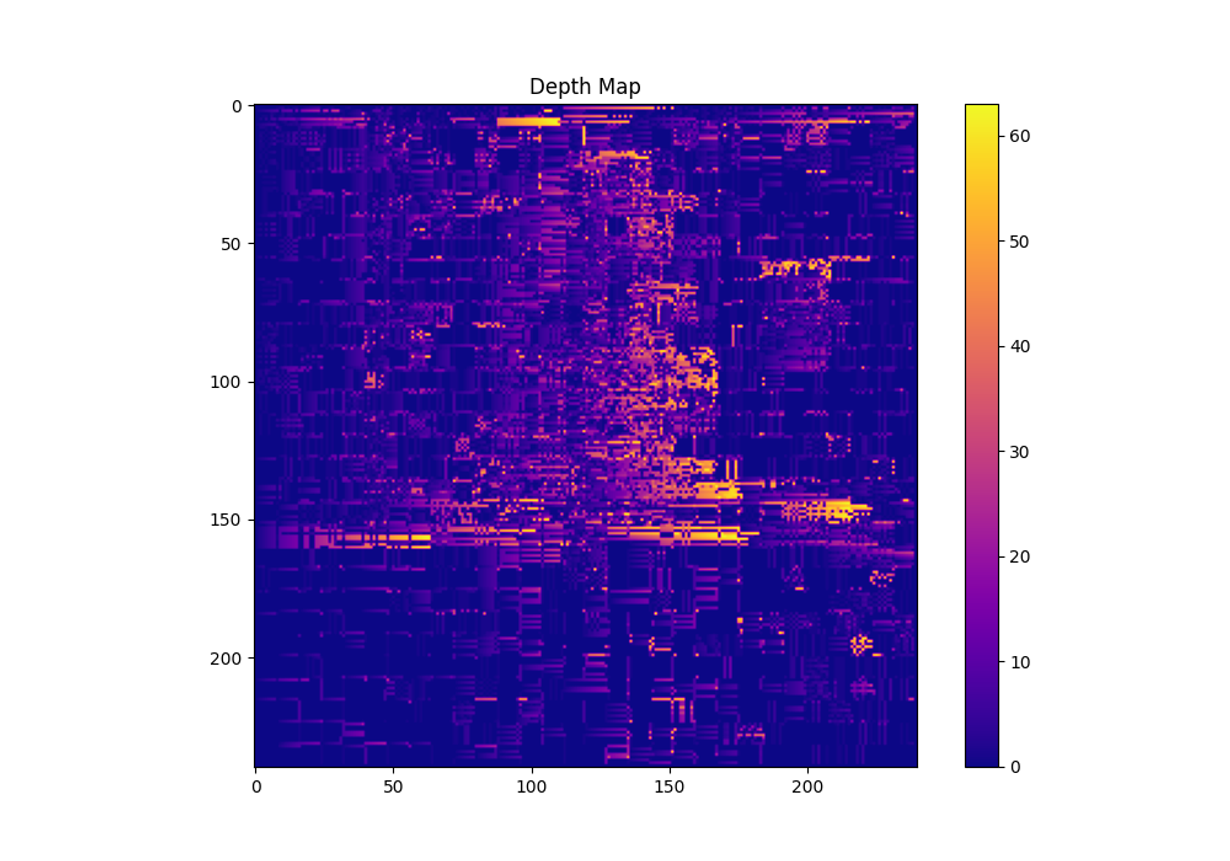
CNNv3: Rank Transform
1. Rank Transform
• 각 픽셀의 ₩을 계산하기 위해 주어진 윈도우 크기 내에서 각 픽셀 값을 주변 값들과 비교하여 순위를 매깁니다.
• 윈도우 내에서 중심 픽셀보다 작은 값의 개수를 세어 Rank Transform 이미지를 생성합니다.
2. 정합 비용 계산
• Rank Transform 된 이미지를 이용하여 좌우 이미지 간의 정합 비용을 계산합니다.
• 각 픽셀의 시차(disparity)를 찾고, 이를 Disparity Map으로 저장합니다.
3. Depth Map 시각화: 계산된 Disparity Map을 시각화하여 Depth Map을 출력합니다.
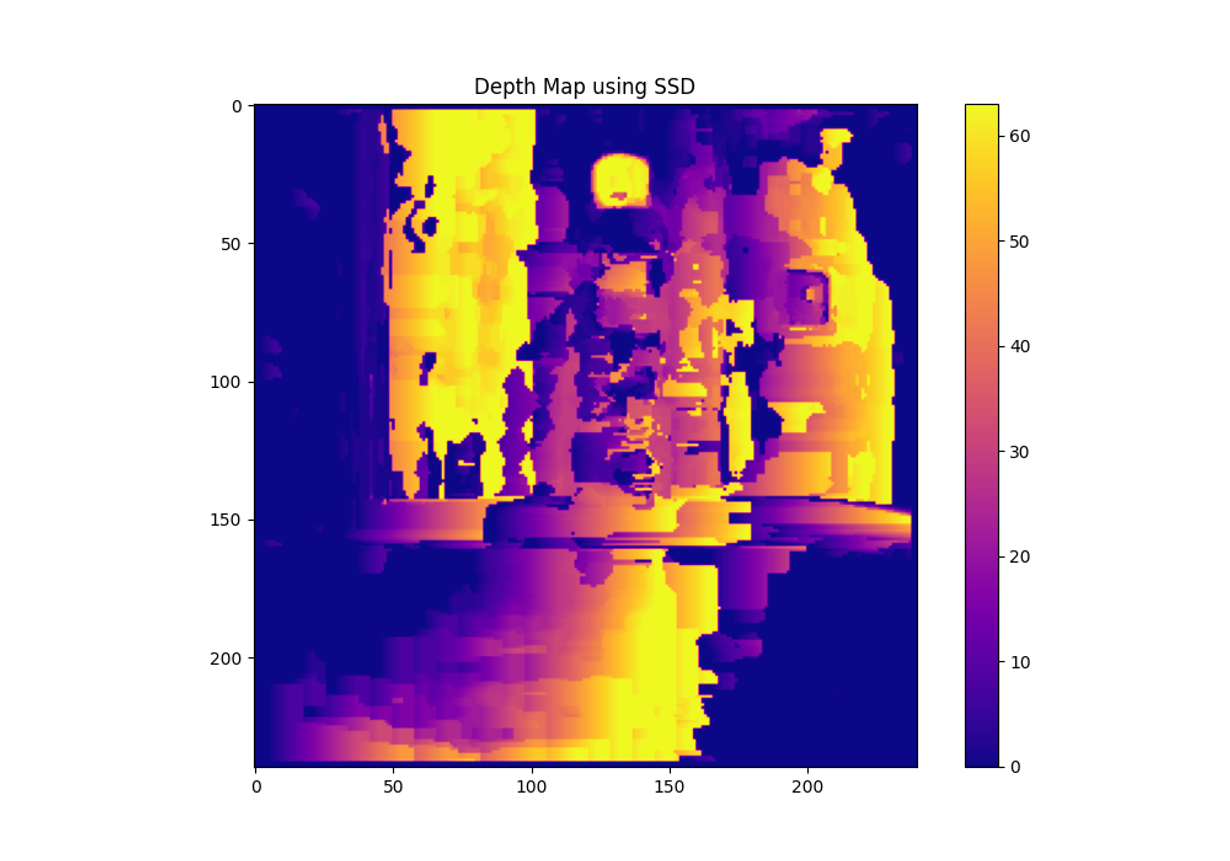
CNNv4: SSD
Sum of Squared Differences (SSD)는 이미지 처리에서 주로 사용되는 용어로, 두 이미지나 패치(patch) 사이의 유사성을 측정하는 방법 중 하나입니다. 주로 스테레오 비전이나 영상 정합(image matching)에서 두 이미지 간의 픽셀 차이를 계산하는 데 사용됩니다. 두 이미지의 각 픽셀 값의 차이를 제곱한 후 모두 더한 값이 SSD입니다. 이 값이 작을수록 두 이미지가 더 유사하다는 의미입니다.
SSD는 다음과 같은 방식으로 계산됩니다:
1. 두 이미지나 패치의 동일한 위치에 있는 픽셀 값의 차이를 계산합니다.
2. 각 픽셀 차이를 제곱하여 양수로 만듭니다.
3. 이 제곱된 값들을 모두 더하여 전체 이미지 또는 패치 간의 유사성을 나타내는 하나의 값으로 표현합니다.
20~60초 이내 분석
SSD 알고리즘을 이용해 스테레오 비전을 구현하고, Depth Map을 생성하여 화면에 출력하는 코드를 작성이 목표.
SSD 알고리즘은 지역 정합 방법 중 하나로, 두 이미지 간의 픽셀 간 차이를 제곱한 값을 누적하여 정합 비용을 계산합니다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 이미지 경로 설정
left_image_path = '/Users/apple/Desktop/Python/Smarcle/MakersDay/StereoCam/SAD/사진자료/left.jpg'
right_image_path = '/Users/apple/Desktop/Python/Smarcle/MakersDay/StereoCam/SAD/사진자료/right.jpg'
# 이미지 읽어오기
left_img = cv2.imread(left_image_path, cv2.IMREAD_GRAYSCALE)
right_img = cv2.imread(right_image_path, cv2.IMREAD_GRAYSCALE)
# 이미지 크기 확인
height, width = left_img.shape
# SSD 알고리즘 적용
def compute_disparity_ssd(left_img, right_img, disparity_range=64, window_size=5):
half_window = window_size // 2
disparity_map = np.zeros_like(left_img, dtype=np.float32)
for y in range(half_window, height - half_window):
for x in range(half_window, width - half_window):
min_ssd = np.inf
best_disparity = 0
for d in range(disparity_range):
ssd = 0
if x - d >= half_window:
for wy in range(-half_window, half_window + 1):
for wx in range(-half_window, half_window + 1):
left_pixel = left_img[y + wy, x + wx]
right_pixel = right_img[y + wy, x + wx - d]
ssd += (left_pixel - right_pixel) ** 2
if ssd < min_ssd:
min_ssd = ssd
best_disparity = d
disparity_map[y, x] = best_disparity
return disparity_map
# 시차 맵 계산
disparity_map = compute_disparity_ssd(left_img, right_img, disparity_range=64, window_size=5)
# Depth map 시각화
plt.figure(figsize=(10, 7))
plt.imshow(disparity_map, cmap='plasma')
plt.colorbar()
plt.title('Depth Map using SSD')
plt.show()#2. mask-RCNN 이용 Depth Map 구현
Mask R-CNN은 객체 검출(Object Detection)과 이미지 분할(Image Segmentation)을 결합한 딥러닝 모델로, 이미지에서 객체의 위치를 탐지하는 것뿐만 아니라 각 객체에 대해 픽셀 단위의 세밀한 마스크를 생성합니다. 이는 객체 검출을 넘어, 이미지의 각 객체를 정확히 분할(Segmentation)하는 데 사용됩니다.
| 특징 | 설명 |
| 객체 검출 및 분할 결합 | 객체 검출(Object Detection)과 이미지 분할(Image Segmentation)을 결합하여 객체의 마스크 생성 |
| 기반 네트워크(Backbone) | ResNet, ResNeXt와 같은 CNN을 사용해 이미지에서 특징을 추출 |
| Region Proposal Network | 이미지에서 객체가 있을 법한 영역(Region of Interest, ROI)을 제안 |
| ROI Align | 제안된 영역을 정확한 크기로 맞추기 위해 ROI Align 기법을 사용, 양자화 오류를 최소화 |
| Bounding Box 예측 | 제안된 영역에서 객체의 경계 상자(Bounding Box)와 클래스(Class)를 예측 |
| Mask 예측 | 각 객체에 대해 픽셀 단위의 마스크를 예측 |
| 픽셀 단위의 정확도 | 객체의 경계를 매우 정밀하게 예측, 객체의 모양을 정확하게 파악하는 데 유리 |
| 응용 분야 | 의료 영상 분석, 자율 주행, 컴퓨터 비전 등에서 활용 |
아래 깃허브를 응용합니다.
GitHub - jonathanrandall/autonomous_task_stereo_cam
Contribute to jonathanrandall/autonomous_task_stereo_cam development by creating an account on GitHub.
github.com
"""----------------------블럭1----------------------"""
import copy
import math
import numpy as np
import cv2
import matplotlib.pyplot as plt
import scipy
import scipy.optimize
import torch
import torchvision
import torchvision.transforms.functional as tvtf
from torchvision.models.detection import MaskRCNN_ResNet50_FPN_Weights,MaskRCNN_ResNet50_FPN_V2_Weights
# from torchvision.models.quantization import ResNet50_QuantizedWeights
# from torchvision.utils import make_grid
# from torchvision.io import read_image
from pathlib import Path
# from torchvision.utils import draw_bounding_boxes
# from torchvision.utils import draw_segmentation_masks
# from torchvision.utils import make_grid
# from torchvision.io import read_image
# from pathlib import Path
# import stereo_image_utils
"""----------------------블럭2----------------------"""
# 여기에 몇 가지 도우미 함수가 있습니다.
# 파일에서 이미지 로드
# 마스크 rcnn 모델에 입력할 이미지를 전처리합니다.
# 이미지 표시
# 두 개의 이미지를 표시하기 위해 이미지 쌍을 표시합니다.
def load_img(filename):
img = cv2.imread(filename)
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
def preprocess_image(image):
image = tvtf.to_tensor(image)
image = image.unsqueeze(dim=0)
return image
def display_image(image):
fig, axes = plt.subplots(figsize=(12, 8))
if image.ndim == 2:
axes.imshow(image, cmap='gray', vmin=0, vmax=255)
else:
axes.imshow(image)
plt.show()
def display_image_pair(first_image, second_image):
#this funciton from Computer vision course notes
# When using plt.subplots, we can specify how many plottable regions we want to create through nrows and ncols
# Here we are creating a subplot with 2 columns and 1 row (i.e. side-by-side axes)
# When we do this, axes becomes a list of length 2 (Containing both plottable axes)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 8))
# TODO: Call imshow on each of the axes with the first and second images
# Make sure you handle both RGB and grayscale images
if first_image.ndim == 2:
axes[0].imshow(first_image, cmap='gray', vmin=0, vmax=255)
else:
axes[0].imshow(first_image)
if second_image.ndim == 2:
axes[1].imshow(second_image, cmap='gray', vmin=0, vmax=255)
else:
axes[1].imshow(second_image)
plt.show()
"""----------------------블럭3----------------------"""
# these colours are used to draw boxes.
COLOURS = [
tuple(int(colour_hex.strip('#')[i:i+2], 16) for i in (0, 2, 4))
for colour_hex in plt.rcParams['axes.prop_cycle'].by_key()['color']
]
"""----------------------블럭4----------------------"""
# I have two images, a left an a right image with my iphone camera. I am holding the camera with my hand
# so it is not an exact grid
d_calib = "50cm"
# path = "C:\\Users\\jonny\\Documents\\Arduino\\Projects\\stereo camera/"
# left_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/clock_240_30_left.jpg'
left_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/240x240/handwatch_240_left.jpg'
#'left_eye_demo2.jpg'
# right_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/clock_240_30_right.jpg'
right_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/240x240/handwatch_240_right.jpg'
#'right_eye_demo2.jpg'
#down sample image to get same size as expected from esp32 cam
left_img = load_img(left_eye)
# left_img = cv2.resize(left_img, dsize=(sz1,sz2), interpolation=cv2.INTER_LINEAR)
right_img = load_img(right_eye)
# right_img = cv2.resize(right_img, dsize=(sz1,sz2), interpolation=cv2.INTER_LINEAR)
sz1 = right_img.shape[1]
sz2 = right_img.shape[0]
display_image_pair(left_img, right_img)
imgs = [left_img, right_img]
left_right = [preprocess_image(d).squeeze(dim=0) for d in imgs]
print(right_img.shape)
"""----------------------블럭5----------------------"""
# 기본 가중치를 사용하고 모델을 설정합니다
weights=MaskRCNN_ResNet50_FPN_V2_Weights.DEFAULT
model = torchvision.models.detection.maskrcnn_resnet50_fpn_v2(weights=weights)
_ = model.eval()
"""----------------------블럭6----------------------"""
# 이 함수는 탐지 결과를 반환합니다.
# det는 상자이며 왼쪽 상단과 오른쪽 하단 좌표입니다.
# lbs는 클래스 레이블입니다.
# 점수는 자신감입니다. 우리는 기본값으로 0.5를 사용합니다.
# 마스크는 분할 마스크입니다.
def get_detections(maskrcnn, imgs, score_threshold=0.5):
''' Runs maskrcnn over all frames in vid, storing the detections '''
# Record how long the video is (in frames)
det = [] # 탐지된 상자들의 좌표를 저장할 리스트
lbls = [] # 탐지된 객체들의 클래스 레이블을 저장할 리스트
scores = [] # 탐지된 객체들의 자신감(확률 또는 점수)을 저장할 리스트
masks = [] # 탐지된 객체들의 분할 마스크를 저장할 리스트
# 각 이미지에 대해 탐지 수행
for img in imgs:
with torch.no_grad():
result = maskrcnn(preprocess_image(img))[0] # Mask R-CNN 모델을 통해 탐지 수행
mask = result["scores"] > score_threshold # 점수가 임계값보다 큰 결과만 사용
boxes = result["boxes"][mask].detach().cpu().numpy() # 탐지된 상자들의 좌표 추출
det.append(boxes)
lbls.append(result["labels"][mask].detach().cpu().numpy()) # 탐지된 객체들의 클래스 레이블 추출
scores.append(result["scores"][mask].detach().cpu().numpy()) # 탐지된 객체들의 점수 추출
masks.append(result["masks"][mask]) # 탐지된 객체들의 분할 마스크 추출 (텐서 형태로 저장)
# det는 bounding boxes, lbls는 class labels, scores는 confidences, masks는 segmentation masks
return det, lbls, scores, masks
"""----------------------블럭7----------------------"""
det, lbls, scores, masks = get_detections(model,imgs)
"""----------------------블럭8----------------------"""
print(np.array(weights.meta["categories"])[lbls[0]])
print(np.array(weights.meta["categories"])[lbls[1]])
"""----------------------블럭9----------------------"""
#draws the bounding boxes
def draw_detections(img, det, colours=COLOURS, obj_order = None):
for i, (tlx, tly, brx, bry) in enumerate(det):
if obj_order is not None and len(obj_order) < i:
i = obj_order[i]
i %= len(colours)
c = colours[i]
cv2.rectangle(img, (tlx, tly), (brx, bry), color=colours[i], thickness=2)
#annotate the class labels
def annotate_class(img, det, lbls, conf=None, colours=COLOURS, class_map=weights.meta["categories"]):
for i, ( tlx, tly, brx, bry) in enumerate(det):
txt = class_map[lbls[i]]
if conf is not None:
txt += f' {conf[i]:1.3f}'
# A box with a border thickness draws half of that thickness to the left of the
# boundaries, while filling fills only within the boundaries, so we expand the filled
# region to match the border
offset = 1
cv2.rectangle(img,
(tlx-offset, tly-offset+12),
(tlx-offset+len(txt)*12, tly),
color=colours[i%len(colours)],
thickness=cv2.FILLED)
ff = cv2.FONT_HERSHEY_PLAIN
cv2.putText(img, txt, (tlx, tly-1+12), fontFace=ff, fontScale=1.0, color=(255,)*3)
def draw_instance_segmentation_mask(img, masks):
''' Draws segmentation masks over an img '''
seg_colours = np.zeros_like(img, dtype=np.uint8)
for i, mask in enumerate(masks):
col = (mask[0, :, :, None] * COLOURS[i])
seg_colours = np.maximum(seg_colours, col.astype(np.uint8))
cv2.addWeighted(img, 0.75, seg_colours, 0.75, 1.0, dst=img)
"""----------------------블럭10----------------------"""
fig, axes = plt.subplots(1, 2, figsize=(12, 8))
# imgs1 = imgs.copy()
for i, imgi in enumerate(imgs):
img = imgi.copy()
deti = det[i].astype(np.int32)
draw_detections(img,deti)
masksi = masks[i].detach().cpu().numpy()
annotate_class(img,deti,lbls[i])
# draw_instance_segmentation_mask(img, masksi)
axes[i].imshow(img)
axes[i].axis('off')
axes[i].set_title(f'Frame #{i}')
"""----------------------블럭11----------------------"""
# 두 개의 서브플롯을 생성, 1행 2열로 구성되며 크기는 12x8인치
fig, axes = plt.subplots(1, 2, figsize=(12, 8))
# imgs 배열의 각 이미지를 반복
for i, imgi in enumerate(imgs):
# 현재 이미지를 복사하여 img에 저장
img = imgi.copy()
# 현재 이미지에 대한 탐지 결과를 정수형으로 변환하여 deti에 저장
deti = det[i].astype(np.int32)
# 탐지 결과를 이미지 위에 그리는 함수 호출
draw_detections(img, deti)
# 0.7 미만의 마스크 값을 0으로 설정
masks[i][masks[i] < 0.7] = 0
# 현재 마스크를 CPU로 이동시키고 numpy 배열로 변환하여 masksi에 저장
masksi = masks[i].detach().cpu().numpy()
# 클래스 주석을 이미지에 추가하는 함수 (현재 주석처리됨)
# annotate_class(img, deti, lbls[i])
# 인스턴스 세분화 마스크를 이미지 위에 그리는 함수 호출
draw_instance_segmentation_mask(img, masksi)
# 현재 이미지를 서브플롯에 표시
axes[i].imshow(img)
# 축을 비활성화 (표시하지 않음)
axes[i].axis('off')
# 서브플롯의 제목을 'Frame #i'로 설정
axes[i].set_title(f'Frame #{i}')
"""----------------------블럭12----------------------"""
#get centr, top left and bottom right of boxes
# 바운딩 박스의 중심 좌표를 계산하는 함수
def tlbr_to_center1(boxes):
points = []
# boxes에서 각 바운딩 박스의 좌표 (top-left-x, top-left-y, bottom-right-x, bottom-right-y)를 반복
for tlx, tly, brx, bry in boxes:
# 중심 좌표 계산
cx = (tlx + brx) / 2
cy = (tly + bry) / 2
# 중심 좌표를 points 리스트에 추가
points.append([cx, cy])
return points
# 바운딩 박스의 좌상단(왼쪽 위) 좌표를 계산하는 함수
def tlbr_to_corner(boxes):
points = []
# boxes에서 각 바운딩 박스의 좌표 (top-left-x, top-left-y, bottom-right-x, bottom-right-y)를 반복
for tlx, tly, brx, bry in boxes:
# 좌상단 좌표 계산
cx = tlx
cy = tly
# 좌상단 좌표를 points 리스트에 추가
points.append((cx, cy))
return points
# 바운딩 박스의 우하단(오른쪽 아래) 좌표를 계산하는 함수
def tlbr_to_corner_br(boxes):
points = []
# boxes에서 각 바운딩 박스의 좌표 (top-left-x, top-left-y, bottom-right-x, bottom-right-y)를 반복
for tlx, tly, brx, bry in boxes:
# 우하단 좌표 계산
cx = brx
cy = bry
# 우하단 좌표를 points 리스트에 추가
points.append((cx, cy))
return points
# 바운딩 박스의 넓이를 계산하는 함수
def tlbr_to_area(boxes):
areas = []
# boxes에서 각 바운딩 박스의 좌표 (top-left-x, top-left-y, bottom-right-x, bottom-right-y)를 반복
for tlx, tly, brx, bry in boxes:
# 바운딩 박스의 가로 길이와 세로 길이 계산
width = brx - tlx
height = bry - tly
# 넓이 계산 (절댓값 취함)
area = abs(width * height)
# 계산된 넓이를 areas 리스트에 추가
areas.append(area)
return areas
"""----------------------블럭13----------------------"""
# 각 함수는 두 이미지의 상자들 간의 거리를 계산하는 함수입니다.
# 왼쪽 이미지는 boxes[0], 오른쪽 이미지는 boxes[1]입니다.
# 브로드캐스팅을 사용하여 계산합니다.
# 파이썬에서 열 벡터 - 행 벡터는 행렬을 생성합니다:
# [a] - [c,d] = [a-c, a-d]
# [b] [b-c, b-d]
# 함수: 중심을 기준으로 한 수평 거리 계산
def get_horiz_dist_centre(boxes):
# 왼쪽 이미지(boxes[0])의 중심점 x좌표 추출
pnts1 = np.array(tlbr_to_center1(boxes[0]))[:,0]
# 오른쪽 이미지(boxes[1])의 중심점 x좌표 추출
pnts2 = np.array(tlbr_to_center1(boxes[1]))[:,0]
# 브로드캐스팅을 사용하여 수평 거리 계산
return pnts1[:,None] - pnts2[None]
# 함수: 좌상단 꼭지점을 기준으로 한 수평 거리 계산
def get_horiz_dist_corner_tl(boxes):
# 왼쪽 이미지(boxes[0])의 좌상단 꼭지점 x좌표 추출
pnts1 = np.array(tlbr_to_corner(boxes[0]))[:,0]
# 오른쪽 이미지(boxes[1])의 좌상단 꼭지점 x좌표 추출
pnts2 = np.array(tlbr_to_corner(boxes[1]))[:,0]
# 브로드캐스팅을 사용하여 수평 거리 계산
return pnts1[:,None] - pnts2[None]
# 함수: 우하단 꼭지점을 기준으로 한 수평 거리 계산
def get_horiz_dist_corner_br(boxes):
# 왼쪽 이미지(boxes[0])의 우하단 꼭지점 x좌표 추출
pnts1 = np.array(tlbr_to_corner_br(boxes[0]))[:,0]
# 오른쪽 이미지(boxes[1])의 우하단 꼭지점 x좌표 추출
pnts2 = np.array(tlbr_to_corner_br(boxes[1]))[:,0]
# 브로드캐스팅을 사용하여 수평 거리 계산
return pnts1[:,None] - pnts2[None]
# 함수: 중심을 기준으로 한 수직 거리 계산
def get_vertic_dist_centre(boxes):
# 왼쪽 이미지(boxes[0])의 중심점 y좌표 추출
pnts1 = np.array(tlbr_to_center1(boxes[0]))[:,1]
# 오른쪽 이미지(boxes[1])의 중심점 y좌표 추출
pnts2 = np.array(tlbr_to_center1(boxes[1]))[:,1]
# 브로드캐스팅을 사용하여 수직 거리 계산
return pnts1[:,None] - pnts2[None]
# 함수: 면적 차이 계산
def get_area_diffs(boxes):
# 왼쪽 이미지(boxes[0])의 상자 면적 추출
pnts1 = np.array(tlbr_to_area(boxes[0]))
# 오른쪽 이미지(boxes[1])의 상자 면적 추출
pnts2 = np.array(tlbr_to_area(boxes[1]))
# 브로드캐스팅을 사용하여 면적 차이 계산
return abs(pnts1[:,None] - pnts2[None])
"""----------------------블럭14----------------------"""
# 블럭14에 해당하는 코드입니다. 이 코드는 상자의 꼭지점과 중심 간의 거리를 계산하는 함수들을 포함하고 있습니다.
# 중심점을 이미지의 가로 길이의 절반으로 설정합니다.
centre = sz1/2
# 함수: 좌상단 꼭지점에서 중심점까지의 거리 계산
def get_dist_to_centre_tl(box, cntr=centre):
# 상자의 좌상단 꼭지점의 x 좌표를 추출합니다.
pnts = np.array(tlbr_to_corner(box))[:,0]
# 꼭지점의 x 좌표와 중심점(cntr) 사이의 거리를 절대값으로 계산하여 반환합니다.
return abs(pnts - cntr)
# 함수: 우하단 꼭지점에서 중심점까지의 거리 계산
def get_dist_to_centre_br(box, cntr=centre):
# 상자의 우하단 꼭지점의 x 좌표를 추출합니다.
pnts = np.array(tlbr_to_corner_br(box))[:,0]
# 꼭지점의 x 좌표와 중심점(cntr) 사이의 거리를 절대값으로 계산하여 반환합니다.
return abs(pnts - cntr)
"""----------------------블럭15----------------------"""
# 블럭15에 해당하는 코드입니다. 이 코드는 함수를 호출하고 결과를 출력하는 예제입니다.
# 첫 번째 상자(det[0])의 우하단 꼭지점에서 중심점까지의 거리를 계산하여 tmp1에 저장합니다.
tmp1 = get_dist_to_centre_br(det[0])
# 두 번째 상자(det[1])의 우하단 꼭지점에서 중심점까지의 거리를 계산하여 tmp2에 저장합니다.
tmp2 = get_dist_to_centre_br(det[1])
# tmp1과 tmp2의 값을 출력합니다.
print(tmp1)
print(tmp2)
"""----------------------블럭16----------------------"""
# 블럭16에 해당하는 코드입니다. 이 코드는 추적 비용 함수를 생성하는 함수입니다. 세 가지 부분으로 구성됩니다.
# 1. 객체의 중심 질량의 수직 이동. 이 부분은 크게 중요하지 않다고 가정하고 스케일을 크게 증가시킵니다.
# 2. 객체의 좌우 이동. 우측으로만 이동할 것으로 예상되므로 왼쪽으로 이동하는 경우에는 패널티를 부여합니다.
# 3. 픽셀 면적의 차이. 이미지의 너비 x 높이로 구성된 면적을 계산하고, 높이로 나누어 최대 값이 너비가 되도록 합니다.
def get_cost(boxes, lbls=None, sz1=400):
# 상수 설정
alpha = sz1 # 이미지의 가로 길이
beta = 10 # 좌우 이동 패널티 계수
gamma = 5 # 수직 이동 스케일 계수
# 1. 객체의 중심 질량의 수직 이동
vert_dist = gamma * abs(get_vertic_dist_centre(boxes))
# 2. 객체의 좌우 이동
horiz_dist = get_horiz_dist_centre(boxes)
horiz_dist[horiz_dist < 0] = beta * abs(horiz_dist[horiz_dist < 0]) # 좌측 이동에 대해 패널티 부여
# 3. 픽셀 면적의 차이
area_diffs = get_area_diffs(boxes) / alpha
# 비용 계산
cost = np.array([vert_dist, horiz_dist, area_diffs])
cost = cost.sum(axis=0) # 각 요소별 합 계산
# 다른 객체 클래스에 대한 패널티 항 추가
if lbls is not None:
for i in range(cost.shape[0]):
for j in range(cost.shape[1]):
if lbls[0][i] != lbls[1][j]:
cost[i, j] += 150 # 클래스가 다른 경우 패널티 추가
return cost
"""----------------------블럭17----------------------"""
# 블럭17에 해당하는 코드입니다. 이 코드는 객체 추적 비용 함수를 계산하는 데 사용되는 함수들을 포함합니다.
# 함수: 객체 중심 질량을 고려한 추적 비용 계산
def get_cost_with_com(masks, lbls=None, prob_thresh=0.7):
alpha = 240 # 이미지의 가로 길이에 해당하는 상수
beta = 10 # 좌우 이동 패널티 계수
gamma = 5 # 수직 이동 스케일 계수
# 좌측 이미지 마스크 처리
mask_bool = masks[0] > prob_thresh # 확률 임계값을 넘는 마스크 선택
mask_bool = mask_bool.squeeze(1) # 차원 축소
# 우측 이미지 마스크 처리
mask_bool2 = masks[1] > prob_thresh # 확률 임계값을 넘는 마스크 선택
mask_bool2 = mask_bool2.squeeze(1) # 차원 축소
# 좌측 이미지의 매개변수 계산
mask_size = (mask_bool).sum(dim=[1,2]) # 마스크 영역 크기 계산
mask_com_matrix_1 = torch.tensor(range(mask_bool.shape[1]))
com1 = ((mask_com_matrix_1.unsqueeze(1)) * mask_bool).sum(dim=[1,2]) / mask_size # 높이 방향의 중심 질량 계산
mask_com_matrix_2 = torch.tensor(range(mask_bool.shape[2]))
com2 = ((mask_com_matrix_2.unsqueeze(0)) * mask_bool).sum(dim=[1,2]) / mask_size # 너비 방향의 중심 질량 계산
left_params = torch.stack((com1, com2, mask_size)).transpose(1,0) # 좌측 이미지의 매개변수 결합
# 우측 이미지의 매개변수 계산
mask_size2 = (mask_bool2).sum(dim=[1,2]) # 마스크 영역 크기 계산
mask_com_matrix_12 = torch.tensor(range(mask_bool2.shape[1]))
com12 = ((mask_com_matrix_12.unsqueeze(1)) * mask_bool2).sum(dim=[1,2]) / mask_size2 # 높이 방향의 중심 질량 계산
mask_com_matrix_22 = torch.tensor(range(mask_bool2.shape[2]))
com22 = ((mask_com_matrix_22.unsqueeze(0)) * mask_bool2).sum(dim=[1,2]) / mask_size2 # 너비 방향의 중심 질량 계산
right_params = torch.stack((com12, com22, mask_size2)).transpose(1,0) # 우측 이미지의 매개변수 결합
# 비용 함수 계산
cost = (left_params[:, None] - right_params[None]) # 좌측 객체와 우측 객체 간의 매개변수 차이 계산
cost[:, :, 2] = abs(cost[:, :, 2]) / alpha # 객체 영역 크기를 이미지 가로 길이에 대해 정규화
# 우측으로 이동할 수 없으므로 좌측 이동에 대해 패널티 부여
cost[cost[:, :, 1] < 0] = beta * abs(cost[cost[:, :, 1] < 0]) # 좌측 이동에 대해 패널티 부여
# 수직 이동에 대해 절대값 적용
cost[:, :, 0] = gamma * abs(cost[:, :, 0]) # 수직 이동에 대해 패널티 부여
cost = cost.sum(dim=2) # 모든 차원의 합 계산
# 클래스가 다른 경우 추가 패널티 부여
if lbls is not None:
for i in range(cost.shape[0]):
for j in range(cost.shape[1]):
if lbls[0][i] != lbls[1][j]:
cost[i, j] += 100 # 클래스가 다른 경우 추가 패널티 부여
return cost
# 함수: 객체 중심 질량을 고려한 수평 거리 계산
def get_horiz_dist(masks, prob_thresh=0.7):
# 각 객체의 중심 질량을 사용하여 수평 거리를 계산합니다.
# 좌측 이미지 마스크 처리
mask_bool = masks[0] > prob_thresh # 확률 임계값을 넘는 마스크 선택
mask_bool = mask_bool.squeeze(1) # 차원 축소
# 우측 이미지 마스크 처리
mask_bool2 = masks[1] > prob_thresh # 확률 임계값을 넘는 마스크 선택
mask_bool2 = mask_bool2.squeeze(1) # 차원 축소
# 좌측 이미지의 매개변수 계산
mask_size = (mask_bool).sum(dim=[1,2]) # 마스크 영역 크기 계산
mask_com_matrix_1 = torch.tensor(range(mask_bool.shape[1]))
com1 = ((mask_com_matrix_1.unsqueeze(1)) * mask_bool).sum(dim=[1,2]) / mask_size # 높이 방향의 중심 질량 계산
mask_com_matrix_2 = torch.tensor(range(mask_bool.shape[2]))
com2 = ((mask_com_matrix_2.unsqueeze(0)) * mask_bool).sum(dim=[1,2]) / mask_size # 너비 방향의 중심 질량 계산
left_params = torch.stack((com1, com2, mask_size)).transpose(1,0) # 좌측 이미지의 매개변수 결합
# 우측 이미지의 매개변수 계산
mask_size2 = (mask_bool2).sum(dim=[1,2]) # 마스크 영역 크기 계산
mask_com_matrix_12 = torch.tensor(range(mask_bool2.shape[1]))
com12 = ((mask_com_matrix_12.unsqueeze(1)) * mask_bool2).sum(dim=[1,2]) / mask_size2 # 높이 방향의 중심 질량 계산
mask_com_matrix_22 = torch.tensor(range(mask_bool2.shape[2]))
com22 = ((mask_com_matrix_22.unsqueeze(0)) * mask_bool2).sum(dim=[1,2]) / mask_size2 # 너비 방향의 중심 질량 계산
right_params = torch.stack((com12, com22, mask_size2)).transpose(1,0) # 우측 이미지의 매개변수 결합
# 수평 거리 계산
cost = (left_params[:, None] - right_params[None]) # 좌측 객체와 우측 객체 간의 매개변수 차이 계산
return cost[:, :, 1] # 너비 방향의 중심 질량 차이 반환
"""----------------------블럭18----------------------"""
# 블럭18에 해당하는 코드입니다. 이 블럭은 객체 추적을 위해 사용되는 함수들을 정의합니다.
# 함수: 선형 할당 문제를 풀어 추적 경로 반환
def get_tracks(cost):
return scipy.optimize.linear_sum_assignment(cost)
# scipy의 linear_sum_assignment 함수를 사용하여 주어진 비용 행렬에서 최적의 할당 문제를 해결하고,
# 좌표 튜플 (row_indices, col_indices)을 반환합니다. 여기서 row_indices는 행의 인덱스, col_indices는 해당 행에 매칭된 열의 인덱스입니다.
# 함수: 선형 할당 문제를 풀어 추적 경로를 행렬 형태로 반환
def get_tracks_ij(cost):
tracks = scipy.optimize.linear_sum_assignment(cost)
# scipy의 linear_sum_assignment 함수를 사용하여 주어진 비용 행렬에서 최적의 할당 문제를 해결하고,
# 좌표 튜플 (row_indices, col_indices)을 tracks 변수에 저장합니다.
# 리스트 내포를 사용하여 tracks 변수에서 각 행의 인덱스와 해당 행에 매칭된 열의 인덱스를 조합하여 2차원 리스트 형태로 반환합니다.
return [[i, j] for i, j in zip(*tracks)]
"""----------------------블럭19----------------------"""
# 블럭19에 해당하는 코드입니다. 이 블럭은 객체 추적 비용 행렬을 계산하는 과정을 보여줍니다.
# 함수 호출: get_cost 함수를 사용하여 객체 추적 비용 행렬을 계산합니다.
cost = get_cost(det, lbls=lbls)
# det: 객체 박스 또는 마스크 정보를 포함하는 리스트입니다. 보통 좌우 이미지의 객체 정보가 포함됩니다.
# lbls: 객체의 클래스 레이블이 포함된 리스트입니다. 이 값이 주어지면 객체 클래스가 다른 경우에 추가적인 패널티를 부여할 수 있습니다.
# cost: 계산된 객체 추적 비용 행렬입니다. 이 행렬은 객체 추적 알고리즘에서 객체 간의 매칭과 이동 비용을 나타냅니다.
"""----------------------블럭20----------------------"""
# 블럭20에 해당하는 코드입니다. 이 블럭은 객체 추적 결과를 계산하고 출력하는 과정을 보여줍니다.
# scipy의 linear_sum_assignment 함수를 사용하여 최적의 추적 경로를 계산하고, 결과를 출력합니다.
tracks = scipy.optimize.linear_sum_assignment(cost)
print(tracks)
# 객체 추적 결과를 기반으로 클래스 레이블을 특정 카테고리 이름으로 매핑합니다.
# h_d는 추적된 객체의 클래스 레이블을 해당하는 카테고리 이름으로 매핑한 리스트입니다.
h_d = [[np.array(weights.meta["categories"])[lbls[0]][i], np.array(weights.meta["categories"])[lbls[1]][j]] for i, j in zip(*tracks)]
print(np.array(weights.meta["categories"])[lbls[0]]) # 첫 번째 이미지의 객체들의 카테고리 이름 배열을 출력합니다.
print(h_d) # 객체 추적 결과를 출력합니다.
"""----------------------블럭21----------------------"""
# 블럭21에 해당하는 코드입니다. 이 블럭은 객체의 추적 결과를 기반으로 가장 가까운 코너의 거리를 계산하고 출력하는 과정을 보여줍니다.
# 좌상단 코너와 우하단 코너의 가로 거리를 계산합니다.
dists_tl = get_horiz_dist_corner_tl(det)
dists_br = get_horiz_dist_corner_br(det)
# 최종 거리를 저장할 리스트 초기화
final_dists = []
# 첫 번째 이미지의 좌상단과 우하단 코너에서 중심까지의 거리를 계산합니다.
dctl = get_dist_to_centre_tl(det[0])
dcbr = get_dist_to_centre_br(det[0])
# tracks에서 추적된 결과를 기반으로 반복합니다.
for i, j in zip(*tracks):
# 좌상단 코너가 중심에 더 가까운 경우
if dctl[i] < dcbr[i]:
# 해당 객체의 좌상단 코너 거리와 클래스를 final_dists에 추가합니다.
final_dists.append((dists_tl[i][j], np.array(weights.meta["categories"])[lbls[0]][i]))
else:
# 해당 객체의 우하단 코너 거리와 클래스를 final_dists에 추가합니다.
final_dists.append((dists_br[i][j], np.array(weights.meta["categories"])[lbls[0]][i]))
# 최종 거리 리스트를 출력합니다.
final_dists
"""----------------------블럭22----------------------"""
# 블럭22에 해당하는 코드입니다. 이 블럭은 초점 거리를 계산하고 출력하는 과정을 보여줍니다.
# 초점 거리 계산식을 사용하여 초점 거리(fl)를 계산합니다.
# 50cm 거리에서 병 이미지 사이의 거리는 38.44 픽셀이고,
# 30cm 거리에서 병 이미지 사이의 거리는 68.75 픽셀입니다.
# fl = 30 - 38.44 * 50 / 68.75
fl = 30 - 38.44 * 50 / 68.75
# 계산된 초점 거리(fl)를 출력합니다.
print(fl)
"""----------------------블럭23----------------------"""
# 블럭23에 해당하는 코드입니다. 이 블럭은 각도(theta)를 보정(calibrate)하는 과정을 보여줍니다.
# 주어진 정보를 바탕으로 각도(theta)의 탄젠트 값을 계산합니다.
# 카메라 간의 거리는 7.05 센티미터입니다.
# tantheta = (1/(50-fl))*(7.05/2)*sz1/38.44
tantheta = (1 / (50 - fl)) * (7.05 / 2) * sz1 / 38.44
# 계산된 탄젠트 값(tantheta)을 출력합니다.
print(tantheta)
"""----------------------블럭24----------------------"""
# 블럭24에 해당하는 코드입니다. 이 블럭은 최종 거리(final distances)를 리스트로 출력하는 과정을 보여줍니다.
# 최종 거리(final distances) 리스트를 생성합니다.
# fd = [i for (i,j) in final_dists]
fd = [i for (i,j) in final_dists]
# 최종 거리(final distances) 리스트를 출력합니다.
print(fd)
"""----------------------블럭25----------------------"""
# 블럭25에 해당하는 코드입니다. 이 블럭은 거리를 계산하는 과정을 보여줍니다.
# 주어진 정보를 바탕으로 거리를 계산합니다.
# dists_away = (7.05/2) * sz1 * (1/tantheta) / np.array(fd) + fl
dists_away = (7.05 / 2) * sz1 * (1 / tantheta) / np.array(fd) + fl
# 계산된 거리(dists_away)를 사용하여 거리 값을 계산합니다.
# - (7.05/2): 카메라 간의 거리의 절반
# - sz1: 이미지에서 측정된 픽셀 값과 관련된 정규화 상수
# - (1/tantheta): 이전 블럭에서 계산된 각도의 역수
# - np.array(fd): 최종 거리(final distances)를 NumPy 배열로 변환하여 사용
# - fl: 이전 블럭에서 계산된 초점 거리
# 계산된 거리(dists_away)를 출력하지 않음
"""----------------------블럭26----------------------"""
# 블럭26에 해당하는 코드입니다. 이 블럭은 카테고리와 거리를 출력하는 과정을 보여줍니다.
# 빈 리스트(cat_dist)를 생성하여 카테고리와 거리를 저장합니다.
cat_dist = []
# 거리를 출력하는 반복문입니다. 각 객체에 대해 반복하며 거리와 카테고리 정보를 출력합니다.
for i in range(len(dists_away)):
# 카테고리와 거리를 문자열로 변환하여 cat_dist 리스트에 추가합니다.
cat_dist.append(f'{np.array(weights.meta["categories"])[lbls[0]][i]} {dists_away[i]:.1f}cm')
# 거리와 카테고리 정보를 포맷에 맞추어 출력합니다.
print(f'{np.array(weights.meta["categories"])[lbls[0]][i]} is {dists_away[i]:.1f}cm away')
"""----------------------블럭27----------------------"""
# 블럭27에 해당하는 코드입니다. 이 블럭은 이미지에 클래스 레이블을 주석으로 추가하는 함수를 정의합니다.
def annotate_class2(img, det, lbls, class_map, conf=None, colours=COLOURS):
"""
이미지에 객체의 클래스 레이블을 주석으로 추가하는 함수입니다.
Args:
- img: 주석을 추가할 이미지
- det: 감지된 객체의 경계 상자 좌표 (tlx, tly, brx, bry) 리스트
- lbls: 감지된 객체의 클래스 레이블 리스트
- class_map: 클래스 인덱스에 대응하는 실제 클래스 이름을 매핑한 딕셔너리 또는 리스트
- conf: (옵션) 각 객체의 신뢰도 리스트
- colours: (옵션) 주석에 사용할 색상 리스트
Returns:
- None: 이미지에 주석이 추가된 후 원본 이미지가 변경됩니다.
"""
# 각 객체에 대해 반복하여 클래스 레이블을 이미지에 추가합니다.
for i, (tlx, tly, brx, bry) in enumerate(det):
# 클래스 레이블을 가져옵니다.
txt = class_map[i]
# 신뢰도가 주어진 경우, 클래스 레이블 뒤에 신뢰도를 추가합니다.
if conf is not None:
txt += f' {conf[i]:1.3f}'
# 주석 박스를 그리기 위한 오프셋 설정
offset = 1
# 주석 박스를 그리고 텍스트를 추가합니다.
cv2.rectangle(img,
(tlx - offset, tly - offset + 12),
(tlx - offset + len(txt) * 12, tly),
color=colours[i % len(colours)],
thickness=cv2.FILLED)
# 폰트 설정 및 텍스트 추가
ff = cv2.FONT_HERSHEY_PLAIN
cv2.putText(img, txt, (tlx, tly - 1 + 12), fontFace=ff, fontScale=1.0, color=(255,) * 3)
# 함수 정의에 대한 주석을 포함하여 각 줄마다 설명을 추가하였습니다.
"""----------------------블럭28----------------------"""
# 주어진 tracks의 첫 번째 리스트를 사용하여 cat_dist에서 해당 인덱스의 요소를 리스트로 변환합니다.
list(np.array(cat_dist)[(tracks[0])])
# np.array(cat_dist): cat_dist 리스트를 NumPy 배열로 변환합니다.
# (tracks[0]): tracks의 첫 번째 리스트를 인덱스로 사용하여 cat_dist에서 해당 위치의 요소를 선택합니다.
# list(...): 선택된 요소들을 리스트 형태로 변환하여 반환합니다.
"""----------------------블럭29----------------------"""
# Matplotlib의 subplots 함수를 사용하여 1x2 그리드의 서브 플롯을 생성합니다.
fig, axes = plt.subplots(1, 2, figsize=(12, 8))
# tracks의 첫 번째 리스트와 두 번째 리스트를 t1에 할당합니다.
t1 = [list(tracks[1]), list(tracks[0])]
# 이미지에 대해 반복합니다.
for i, imgi in enumerate(imgs):
# 이미지의 복사본을 img 변수에 할당합니다.
img = imgi.copy()
# det[i]를 정수형으로 변환하여 deti에 할당합니다.
deti = det[i].astype(np.int32)
# draw_detections 함수를 사용하여 이미지에 객체 감지 정보를 그립니다.
# list(tracks[i])를 사용하여 tracks가 가리키는 객체의 인덱스를 선택하고,
# obj_order를 list(t1[i])로 설정하여 해당 순서대로 객체를 그립니다.
draw_detections(img, deti[list(tracks[i])], obj_order=list(t1[i]))
# annotate_class2 함수를 사용하여 이미지에 클래스 레이블을 주석으로 추가합니다.
# deti[list(tracks[i])]를 통해 선택된 객체의 좌표를 전달합니다.
# lbls[i][list(tracks[i])]를 통해 선택된 객체의 클래스 레이블을 전달합니다.
# cat_dist를 사용하여 클래스 레이블과 객체 간의 거리를 표시합니다.
annotate_class2(img, deti[list(tracks[i])], lbls[i][list(tracks[i])], cat_dist)
# 서브 플롯의 i번째 위치에 이미지를 표시합니다.
axes[i].imshow(img)
# 축을 제거합니다.
axes[i].axis('off')
# 서브 플롯의 제목을 설정합니다.
axes[i].set_title(f'Frame #{i}')
# 각 줄마다 설명을 추가하였습니다.이 코드는 Mask R-CNN 모델을 활용하여 ESP32 카메라에서 촬영한 스테레오 비전 이미지를 처리하고 객체 탐지를 수행하는 과정을 설명하는 Jupyter 노트북의 전체 코드입니다. 주요 기능은 이미지 로딩, 전처리, Mask R-CNN을 통한 객체 탐지, 객체 매칭, 거리 계산 등입니다. 아래는 코드의 주요 부분에 대한 설명입니다.
블록별 분석
아래 접은 글을 확인합니다.
- 블록 1-4: 라이브러리 임포트 및 이미지 로드
- 필요한 라이브러리와 패키지를 임포트 하고, 이미지 로드 및 전처리, 시각화 관련 함수들을 정의합니다.
- load_img, preprocess_image, display_image_pair 등의 함수는 이미지 로딩 및 시각화를 담당합니다.
- 블록 5-7: Mask R-CNN 모델 설정 및 객체 탐지
- Mask R-CNN 모델을 설정하고, get_detections 함수를 통해 이미지에서 객체를 탐지합니다.
- 탐지된 객체의 바운딩 박스, 클래스 레이블, 점수, 마스크 등을 반환합니다.
- 블록 8-11: 탐지 결과 시각화
- 탐지된 객체를 이미지에 그리기 위해 바운딩 박스와 클래스 레이블을 그리는 함수들을 정의합니다.
- draw_detections, annotate_class, draw_instance_segmentation_mask 등의 함수가 사용됩니다.
- 탐지 결과를 시각화하는 부분이 포함됩니다.
- 블록 12-14: 바운딩 박스 좌표 계산
- 탐지된 객체의 바운딩 박스 중심 좌표, 코너 좌표, 면적 등을 계산하는 함수들을 정의합니다.
- 이 정보는 이후 객체 매칭과 거리 계산에 사용됩니다.
- 블록 15-21: 객체 매칭 및 거리 계산
- 두 이미지(좌우) 간 객체를 매칭하기 위해 get_cost, get_cost_with_com 등의 함수가 사용됩니다.
- scipy.optimize.linear_sum_assignment를 통해 최적의 객체 매칭을 수행합니다.
- 거리 계산을 통해 객체의 실제 거리를 추정하는 과정이 포함됩니다.
- 블록 22-26: 거리 추정 및 결과 출력
- 초점 거리와 각도 등을 고려하여 객체의 거리를 계산하고, 이를 바탕으로 객체 간의 거리와 위치를 추정합니다.
- 계산된 거리 정보를 카테고리와 함께 출력합니다.
- 블록 27-29: 최종 결과 시각화
- annotate_class2 함수를 통해 객체에 대한 정보를 이미지에 주석으로 추가합니다.
- 최종적으로 탐지된 객체와 계산된 거리를 시각화합니다.
전체 흐름
이 코드의 주요 흐름은 다음과 같습니다:
1. 이미지 로드 및 전처리.
2. Mask R-CNN을 사용한 객체 탐지.
3. 탐지된 객체의 좌표, 클래스, 마스크 등 정보 추출.
4. 좌우 이미지 간 객체 매칭.
5. 객체의 실제 거리 계산.
6. 결과 시각화 및 출력
prototype_v1
코드는 아래 접은 글을 확인합니다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
import torchvision.transforms.functional as tvtf
from torchvision.models.detection import MaskRCNN_ResNet50_FPN_V2_Weights
import scipy.optimize
# 색상 설정
COLOURS = [
tuple(int(colour_hex.strip('#')[i:i+2], 16) for i in (0, 2, 4))
for colour_hex in plt.rcParams['axes.prop_cycle'].by_key()['color']
]
# 이미지 로드 및 전처리 함수
def load_img(filename):
img = cv2.imread(filename)
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
def preprocess_image(image):
image = tvtf.to_tensor(image)
image = image.unsqueeze(dim=0)
return image
# 모델 초기화
weights = MaskRCNN_ResNet50_FPN_V2_Weights.DEFAULT
model = torchvision.models.detection.maskrcnn_resnet50_fpn_v2(weights=weights)
_ = model.eval()
# 탐지 함수
def get_detections(maskrcnn, imgs, score_threshold=0.5):
det, lbls, scores, masks = [], [], [], []
for img in imgs:
with torch.no_grad():
result = maskrcnn(preprocess_image(img))[0]
mask = result["scores"] > score_threshold
det.append(result["boxes"][mask].detach().cpu().numpy())
lbls.append(result["labels"][mask].detach().cpu().numpy())
scores.append(result["scores"][mask].detach().cpu().numpy())
masks.append(result["masks"][mask])
return det, lbls, scores, masks
# 객체의 경계 상자 그리기 및 주석 추가
def draw_detections(img, det, colours=COLOURS):
for i, (tlx, tly, brx, bry) in enumerate(det):
cv2.rectangle(img, (tlx, tly), (brx, bry), color=colours[i % len(colours)], thickness=2)
def annotate_class_with_distance(img, det, lbls, distances, class_map=weights.meta["categories"], colours=COLOURS):
for i, (tlx, tly, brx, bry) in enumerate(det):
txt = f'{class_map[lbls[i]]} {distances[i]:.1f}cm'
cv2.rectangle(img, (tlx, tly-12), (tlx + len(txt)*12, tly), color=colours[i % len(colours)], thickness=cv2.FILLED)
cv2.putText(img, txt, (tlx, tly-1), fontFace=cv2.FONT_HERSHEY_PLAIN, fontScale=1.0, color=(255,) * 3)
# 중심 좌표 계산 함수
def tlbr_to_center1(boxes):
points = []
for tlx, tly, brx, bry in boxes:
cx = (tlx + brx) / 2
cy = (tly + bry) / 2
points.append([cx, cy])
return points
# 수직 거리 계산 함수
def get_vertic_dist_centre(boxes):
pnts1 = np.array(tlbr_to_center1(boxes[0]))[:,1]
pnts2 = np.array(tlbr_to_center1(boxes[1]))[:,1]
return pnts1[:,None] - pnts2[None]
# 수평 거리 계산 함수
def get_horiz_dist_centre(boxes):
pnts1 = np.array(tlbr_to_center1(boxes[0]))[:,0]
pnts2 = np.array(tlbr_to_center1(boxes[1]))[:,0]
return pnts1[:,None] - pnts2[None]
# 면적 차이 계산 함수
def get_area_diffs(boxes):
areas1 = []
areas2 = []
for box in boxes[0]:
tlx, tly, brx, bry = box
width = brx - tlx
height = bry - tly
area = abs(width * height)
areas1.append(area)
for box in boxes[1]:
tlx, tly, brx, bry = box
width = brx - tlx
height = bry - tly
area = abs(width * height)
areas2.append(area)
areas1 = np.array(areas1)
areas2 = np.array(areas2)
return abs(areas1[:, None] - areas2[None])
# 비용 행렬 계산
def get_cost(boxes, lbls=None, sz1=400):
alpha, beta, gamma = sz1, 10, 5
vert_dist = gamma * abs(get_vertic_dist_centre(boxes))
horiz_dist = get_horiz_dist_centre(boxes)
horiz_dist[horiz_dist < 0] = beta * abs(horiz_dist[horiz_dist < 0])
area_diffs = get_area_diffs(boxes) / alpha
cost = vert_dist + horiz_dist + area_diffs
if lbls is not None:
for i in range(cost.shape[0]):
for j in range(cost.shape[1]):
if lbls[0][i] != lbls[1][j]:
cost[i, j] += 150
return cost
# 주어진 이미지 경로
# left_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/240x240/handwatch_240_left.jpg'
# right_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/240x240/handwatch_240_right.jpg'
left_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/240x240/clock_240_30_left_suc.jpg'
right_eye = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/240x240/clock_240_30_right_suc.jpg'
# 이미지 로드 및 전처리
left_img = load_img(left_eye)
right_img = load_img(right_eye)
imgs = [left_img, right_img]
# 탐지 수행
det, lbls, scores, masks = get_detections(model, imgs)
# 비용 행렬 계산 및 매칭
cost = get_cost(det, lbls=lbls)
tracks = scipy.optimize.linear_sum_assignment(cost)
# 거리 계산
fl = 30 - 38.44 * 50 / 68.75
tantheta = (1 / (50 - fl)) * (7.05 / 2) * right_img.shape[1] / 38.44
# 코너 기반 거리 계산 함수들 추가
def tlbr_to_corner(boxes):
points = []
for tlx, tly, brx, bry in boxes:
points.append((tlx, tly))
return points
def tlbr_to_corner_br(boxes):
points = []
for tlx, tly, brx, bry in boxes:
points.append((brx, bry))
return points
def get_horiz_dist_corner_tl(boxes):
pnts1 = np.array(tlbr_to_corner(boxes[0]))[:,0]
pnts2 = np.array(tlbr_to_corner(boxes[1]))[:,0]
return pnts1[:,None] - pnts2[None]
def get_horiz_dist_corner_br(boxes):
pnts1 = np.array(tlbr_to_corner_br(boxes[0]))[:,0]
pnts2 = np.array(tlbr_to_corner_br(boxes[1]))[:,0]
return pnts1[:,None] - pnts2[None]
def get_dist_to_centre_tl(box, cntr=None):
cntr = cntr if cntr else right_img.shape[1] / 2
pnts = np.array(tlbr_to_corner(box))[:,0]
return abs(pnts - cntr)
def get_dist_to_centre_br(box, cntr=None):
cntr = cntr if cntr else right_img.shape[1] / 2
pnts = np.array(tlbr_to_corner_br(box))[:,0]
return abs(pnts - cntr)
# 거리 계산
dists_tl = get_horiz_dist_corner_tl(det)
dists_br = get_horiz_dist_corner_br(det)
final_dists = []
dctl = get_dist_to_centre_tl(det[0])
dcbr = get_dist_to_centre_br(det[0])
for i, j in zip(*tracks):
if dctl[i] < dcbr[i]:
final_dists.append((dists_tl[i][j], np.array(weights.meta["categories"])[lbls[0]][i]))
else:
final_dists.append((dists_br[i][j], np.array(weights.meta["categories"])[lbls[0]][i]))
fd = [i for (i, j) in final_dists]
dists_away = (7.05 / 2) * right_img.shape[1] * (1 / tantheta) / np.array(fd) + fl
# 최종 결과 표시
fig, axes = plt.subplots(1, 2, figsize=(12, 8))
for i, imgi in enumerate(imgs):
img = imgi.copy()
deti = det[i].astype(np.int32)
draw_detections(img, deti[list(tracks[i])])
annotate_class_with_distance(img, deti[list(tracks[i])], lbls[i][list(tracks[i])], dists_away)
axes[i].imshow(img)
axes[i].axis('off')
axes[i].set_title(f'Frame #{i}')
plt.show()코드는 Mask R-CNN 모델을 사용하여 두 이미지에서 객체를 탐지하고, 탐지된 객체들의 위치와 종류를 기반으로 거리 계산을 수행합니다. 주요 단계는 다음과 같습니다:
1. 색상 설정: 객체 경계 상자 및 주석에 사용할 색상들을 설정합니다.
2. 이미지 로드 및 전처리: 이미지를 로드하고 RGB로 변환한 후, 텐서로 변환합니다.
3. 모델 초기화: Mask R-CNN 모델을 로드하고 평가 모드로 설정합니다.
4. 탐지 수행: 모델을 사용하여 객체를 탐지하고, 경계 상자, 레이블, 점수 및 마스크를 추출합니다.
5. 경계 상자 및 주석 추가: 탐지된 객체들의 경계 상자를 그리고, 레이블과 거리를 주석으로 추가합니다.
6. 거리 계산: 두 이미지에서 탐지된 객체들의 중심 및 코너 좌표를 이용해 거리 및 비용 행렬을 계산하고, 최적의 매칭을 찾습니다.
7. 결과 표시: 두 이미지에 탐지된 객체들과 주석을 표시합니다.

#3. YOLO 기반 스테레오 카메라 구현
YOLO(You Only Look Once)는 실시간 객체 탐지(Object Detection) 알고리즘으로, 이미지를 한 번만 처리하여 이미지 내 여러 객체의 위치와 종류를 동시에 예측하는 모델입니다. YOLO는 매우 빠르고 효율적이어서 실시간 애플리케이션에 적합합니다.
YOLO(You Only Look Once) 알고리즘은 이미지에서 객체를 탐지하는 과정을 단일 신경망을 통해 처리합니다. 먼저, 입력 이미지를 정사각형 형태로 변환하여 네트워크에 입력합니다. 이 네트워크는 이미지를 격자 셀로 나누고, 각 셀에서 객체의 존재 여부와 위치, 클래스 정보를 동시에 예측합니다.
각 격자 셀은 객체가 포함되어 있을 수 있는 지역을 나타내며, 이 셀은 예측된 클래스와 함께 객체의 경계 상자(Bounding Box) 정보를 제공합니다. YOLO는 이미지 전체를 한 번만 처리하기 때문에 실시간으로 객체를 탐지할 수 있습니다. 네트워크는 모든 격자 셀의 예측을 통합하여 최종적으로 이미지 내의 객체를 식별하고 위치를 표시합니다. 이 과정에서 YOLO는 이미지의 전반적인 맥락을 활용해 객체 간의 관계를 잘 반영합니다.
아래는 YOLO의 장점과 단점을 정리한 표입니다.
| 처리 속도 | 매우 빠른 실시간 처리 가능, 단일 네트워크로 빠르게 예측 | 높은 정확도를 위해 추가적인 처리가 필요할 수 있음, 속도와 정확도 간의 트레이드오프 발생 가능 |
| 전체 맥락 활용 | 이미지 전체를 고려하여 객체 간의 관계를 잘 반영할 수 있음 | 작은 객체나 겹쳐 있는 객체의 탐지에서 성능이 떨어질 수 있음 |
| 단일 네트워크 | 단일 네트워크 구조로 간단하고 일관된 예측이 가능 | 네트워크 구조가 복잡해질 수 있으며, 초기 설정과 학습에 많은 자원이 필요할 수 있음 |
| 다중 객체 탐지 | 한 번의 실행으로 여러 객체를 동시에 탐지하고 분류 가능 | 예측된 경계 상자의 정확도가 낮을 수 있으며, 격자 셀 크기에 따라 성능 저하가 발생할 수 있음 |
| 학습과 추론 | 학습과 추론이 상대적으로 간단하여 구현과 유지보수가 용이 | 큰 객체와 작은 객체 간의 성능 차이가 클 수 있으며, 특히 작은 객체에 대한 탐지가 약할 수 있음 |
스테레오 카메라 알고리즘 제작 | Notion
#1. CNN 이용 Depth Map 구현
udangtangtang-cording-oldcast1e.notion.site
YOLO을 스테레오 비전에 응용하면 객체 탐지와 깊이 정보를 동시에 활용할 수 있습니다. YOLO는 실시간으로 이미지 내 객체를 정확하게 식별하고 위치를 찾는 데 강점을 가지며, 스테레오 비전은 두 카메라를 사용해 깊이 정보를 제공합니다. 이 결합으로 객체의 정확한 위치와 그 객체까지의 거리 정보를 함께 얻을 수 있습니다. 이러한 통합은 자율 주행차나 로봇이 환경을 보다 정밀하게 인식하고 실시간으로 대응할 수 있게 합니다.
이러한 YOLO의 장점을 반영해
실시간으로 객체 간의 거리와 카테고리를 판단하는 것이 이 프로젝트의 목표이다.
아래는 YOLO를 이용한 스테레오 카메라의 각 버전 설명입니다.
✅ 렌즈 상수
#focal length. Pre-calibrated in stereo_image_v6 notebook fl = 2.043636363636363 tantheta = 0.7648732789907391

/Users/apple/Desktop/Python/Smarcle/MakersDay/StereoCam/과정/YOLO/YOLOv1.py
YOLOv1~YOLOv2
import torch
import cv2
import numpy as np
# YOLOv5 모델 로드
def load_model(weights_path):
model = torch.hub.load('ultralytics/yolov5', 'custom', path=weights_path)
return model
# 이미지에서 객체 탐지
def detect_objects(model, img):
results = model(img)
return results
# 바운더리 박스와 라벨을 가져오기
def get_bounding_boxes(results):
labels = results.xyxyn[0][:,-1].numpy()
boxes = results.xyxyn[0][:,:-1].numpy()
return labels, boxes
# 카메라와 객체 사이의 거리를 계산하는 함수
def calculate_distance(box1, box2, fl, tantheta, img_width):
center1 = (box1[0] + box1[2]) / 2 * img_width
center2 = (box2[0] + box2[2]) / 2 * img_width
disparity = abs(center1 - center2)
distance = (7.05 / 2) * img_width * (1 / tantheta) / disparity + fl
return distance
# 같은 카테고리 객체 사이의 거리 계산
def compute_distances_between_objects(labels1, boxes1, labels2, boxes2, fl, tantheta, img_width):
distances = {}
for i, label in enumerate(labels1):
if label in labels2:
j = np.where(labels2 == label)[0][0]
distance = calculate_distance(boxes1[i], boxes2[j], fl, tantheta, img_width)
distances[label] = distance
return distances
# 이미지에 객체 카테고리와 거리를 표시
def annotate_image_with_distances(img, labels, boxes, distances, class_map):
for i, (label, box) in enumerate(zip(labels, boxes)):
category = class_map[int(label)]
distance = distances[label]
x1, y1, x2, y2 = int(box[0] * img.shape[1]), int(box[1] * img.shape[0]), int(box[2] * img.shape[1]), int(box[3] * img.shape[0])
# 경계 상자 그리기
cv2.rectangle(img, (x1, y1), (x2, y2), color=(0, 255, 0), thickness=2)
# 객체의 카테고리와 거리를 표시하는 텍스트
text = f'{category}: {distance:.2f}m'
cv2.putText(img, text, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return img
# YOLOv5의 실제 카테고리 이름을 사용하는 클래스 맵
CLASS_MAP = {
0: "person", 1: "bicycle", 2: "car", 3: "motorcycle", 4: "airplane", 5: "bus", 6: "train",
7: "truck", 8: "boat", 9: "traffic light", 10: "fire hydrant", 11: "stop sign", 12: "parking meter",
13: "bench", 14: "bird", 15: "cat", 16: "dog", 17: "horse", 18: "sheep", 19: "cow",
20: "elephant", 21: "bear", 22: "zebra", 23: "giraffe", 24: "backpack", 25: "umbrella",
26: "handbag", 27: "tie", 28: "suitcase", 29: "frisbee", 30: "skis", 31: "snowboard",
32: "sports ball", 33: "kite", 34: "baseball bat", 35: "baseball glove", 36: "skateboard",
37: "surfboard", 38: "tennis racket", 39: "bottle", 40: "wine glass", 41: "cup", 42: "fork",
43: "knife", 44: "spoon", 45: "bowl", 46: "banana", 47: "apple", 48: "sandwich", 49: "orange",
50: "broccoli", 51: "carrot", 52: "hot dog", 53: "pizza", 54: "donut", 55: "cake", 56: "chair",
57: "couch", 58: "potted plant", 59: "bed", 60: "dining table", 61: "toilet", 62: "TV",
63: "laptop", 64: "mouse", 65: "remote", 66: "keyboard", 67: "cell phone", 68: "microwave",
69: "oven", 70: "toaster", 71: "sink", 72: "refrigerator", 73: "book", 74: "clock",
75: "vase", 76: "scissors", 77: "teddy bear", 78: "hair drier", 79: "toothbrush"
}
def load_image(image_path):
img = cv2.imread(image_path)
if img is None:
raise FileNotFoundError(f"이미지를 로드할 수 없습니다: {image_path}")
return img
def main():
# 이미지 경로
img1_path = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/UXGA/clock_UXGA_30_left.jpeg'
img2_path = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/UXGA/clock_UXGA_30_right.jpeg'
# 스테레오 비전 설정
fl = 2.043636363636363
tantheta = 0.7648732789907391
img_width = 240
# YOLOv5 모델 로드
weights_path = '/Users/apple/Desktop/Python/yolov5s.pt'
model = load_model(weights_path)
# 이미지 로드
img1 = load_image(img1_path)
img2 = load_image(img2_path)
# 객체 탐지
results1 = detect_objects(model, img1)
results2 = detect_objects(model, img2)
# 바운더리 박스와 라벨 추출
labels1, boxes1 = get_bounding_boxes(results1)
labels2, boxes2 = get_bounding_boxes(results2)
# 거리 계산
distances = compute_distances_between_objects(labels1, boxes1, labels2, boxes2, fl, tantheta, img_width)
# 거리 출력
for label, distance in distances.items():
category = CLASS_MAP[int(label)]
print(f"Category: {category}, Distance: {distance:.2f} meters")
# 이미지에 주석 추가
img1_annotated = annotate_image_with_distances(img1, labels1, boxes1, distances, CLASS_MAP)
# 최종 이미지 파이썬 창에 띄우기
cv2.imshow("Annotated Image", img1_annotated)
cv2.waitKey(0) # 키 입력이 있을 때까지 창을 유지합니다.
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
• YOLO 사용 결과 해상도가 높을수록 좋은 결과가 나오는 것을 확인할 수 있었음.
• 이미지 처리 시간 약 6초 정도 발생
• 실제값과 6cm 정도의 오차가 발생
YOLOv3 : 시차 터미널 출력 코드 추가
Category: clock, Disparity: 48.93 pixels
Category: clock, Distance: 24.65 meters
YOLOv4
import torch
import cv2
import numpy as np
# YOLOv5 모델 로드
def load_model(weights_path):
model = torch.hub.load('ultralytics/yolov5', 'custom', path=weights_path)
return model
# 이미지에서 객체 탐지
def detect_objects(model, img):
results = model(img)
return results
# 바운더리 박스와 라벨을 가져오기
def get_bounding_boxes(results):
labels = results.xyxyn[0][:,-1].numpy()
boxes = results.xyxyn[0][:,:-1].numpy()
return labels, boxes
# 시차를 계산하는 함수
def calculate_disparity(box1, box2, img_width):
center1 = (box1[0] + box1[2]) / 2 * img_width
center2 = (box2[0] + box2[2]) / 2 * img_width
disparity = abs(center1 - center2)
return disparity
# 카메라와 객체 사이의 거리를 계산하는 함수
def calculate_distance(disparity, fl, tantheta, img_width):
distance = (7.05 / 2) * img_width * (1 / tantheta) / disparity + fl
return distance
# 같은 카테고리 객체 사이의 거리 및 시차 계산
def compute_distances_and_disparity(labels1, boxes1, labels2, boxes2, fl, tantheta, img_width):
distances = {}
disparities = {}
for i, label in enumerate(labels1):
if label in labels2:
j = np.where(labels2 == label)[0][0]
disparity = calculate_disparity(boxes1[i], boxes2[j], img_width)
distance = calculate_distance(disparity, fl, tantheta, img_width)
distances[label] = distance
disparities[label] = disparity
return distances, disparities
# 이미지에 객체 카테고리와 거리를 표시
def annotate_image_with_distances(img, labels, boxes, distances, class_map):
for i, (label, box) in enumerate(zip(labels, boxes)):
category = class_map[int(label)]
distance = distances[label]
x1, y1, x2, y2 = int(box[0] * img.shape[1]), int(box[1] * img.shape[0]), int(box[2] * img.shape[1]), int(box[3] * img.shape[0])
# 경계 상자 그리기
cv2.rectangle(img, (x1, y1), (x2, y2), color=(0, 255, 0), thickness=2)
# 객체의 카테고리와 거리를 표시하는 텍스트
text = f'{category}: {distance:.2f}m'
cv2.putText(img, text, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return img
# YOLOv5의 실제 카테고리 이름을 사용하는 클래스 맵
CLASS_MAP = {
0: "person", 1: "bicycle", 2: "car", 3: "motorcycle", 4: "airplane", 5: "bus", 6: "train",
7: "truck", 8: "boat", 9: "traffic light", 10: "fire hydrant", 11: "stop sign", 12: "parking meter",
13: "bench", 14: "bird", 15: "cat", 16: "dog", 17: "horse", 18: "sheep", 19: "cow",
20: "elephant", 21: "bear", 22: "zebra", 23: "giraffe", 24: "backpack", 25: "umbrella",
26: "handbag", 27: "tie", 28: "suitcase", 29: "frisbee", 30: "skis", 31: "snowboard",
32: "sports ball", 33: "kite", 34: "baseball bat", 35: "baseball glove", 36: "skateboard",
37: "surfboard", 38: "tennis racket", 39: "bottle", 40: "wine glass", 41: "cup", 42: "fork",
43: "knife", 44: "spoon", 45: "bowl", 46: "banana", 47: "apple", 48: "sandwich", 49: "orange",
50: "broccoli", 51: "carrot", 52: "hot dog", 53: "pizza", 54: "donut", 55: "cake", 56: "chair",
57: "couch", 58: "potted plant", 59: "bed", 60: "dining table", 61: "toilet", 62: "TV",
63: "laptop", 64: "mouse", 65: "remote", 66: "keyboard", 67: "cell phone", 68: "microwave",
69: "oven", 70: "toaster", 71: "sink", 72: "refrigerator", 73: "book", 74: "clock",
75: "vase", 76: "scissors", 77: "teddy bear", 78: "hair drier", 79: "toothbrush"
}
def load_image(image_path):
img = cv2.imread(image_path)
if img is None:
raise FileNotFoundError(f"이미지를 로드할 수 없습니다: {image_path}")
return img
def main():
# 이미지 경로
img1_path = "/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/UXGA/bottle_UXGA_50_left.jpeg"
img2_path = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/UXGA/bottle_UXGA_50_right.jpeg'
# img1_path = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/UXGA/clock_UXGA_30_left.jpeg'
# img2_path = '/Users/apple/Desktop/Python/Smarcle/MakersDay/사진자료/UXGA/clock_UXGA_30_right.jpeg'
# 스테레오 비전 설정
fl = 2.043636363636363
"""기존 탄젠트 값"""
# tantheta = 0.7648732789907391
# tantheta = 0.6472684702
tantheta = 0.5884660658
# tantheta = 0.5296636614
# tantheta = 0.2944540438102669
img_width = 240
# YOLOv5 모델 로드
weights_path = '/Users/apple/Desktop/Python/yolov5s.pt'
model = load_model(weights_path)
# 이미지 로드
img1 = load_image(img1_path)
img2 = load_image(img2_path)
# 객체 탐지
results1 = detect_objects(model, img1)
results2 = detect_objects(model, img2)
# 바운더리 박스와 라벨 추출
labels1, boxes1 = get_bounding_boxes(results1)
labels2, boxes2 = get_bounding_boxes(results2)
# 거리 및 시차 계산
distances, disparities = compute_distances_and_disparity(labels1, boxes1, labels2, boxes2, fl, tantheta, img_width)
# 시차 출력
for label, disparity in disparities.items():
category = CLASS_MAP[int(label)]
print(f"Category: {category}, Disparity: {disparity:.2f} pixels")
# 거리 출력
for label, distance in distances.items():
category = CLASS_MAP[int(label)]
print(f"Category: {category}, Distance: {distance:.2f} meters")
# 이미지에 주석 추가
img1_annotated = annotate_image_with_distances(img1, labels1, boxes1, distances, CLASS_MAP)
# 최종 이미지 파이썬 창에 띄우기
cv2.imshow("Annotated Image", img1_annotated)
cv2.waitKey(0) # 키 입력이 있을 때까지 창을 유지합니다.
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
스테레오 정합은 스테레오 비전 시스템에서 가장 중요한 과정 중 하나로, 두 개의 서로 다른 시점(카메라)에서 얻은 이미지를 비교하여 동일한 물체의 대응점을 찾는 과정입니다. 이러한 대응점을 찾음으로써 각 지점의 깊이 정보를 추정할 수 있습니다.
좌/우 이미지
- 스테레오 비전 시스템은 일반적으로 두 개의 카메라를 사용하여 동일한 장면을 촬영합니다.
- 이때 얻어진 두 이미지가 "좌 이미지"와 "우 이미지"입니다.
디스패리티 (Disparity): 이 두 점 간의 좌표 차이
스테레오 정합의 주요 목표는 두 이미지에서 동일한 물체의 점이 서로 어디에 위치하는지를 찾는 것입니다. 디스패리티는 깊이(거리) 정보를 얻는 데 사용됩니다. 디스패리티가 크면 물체가 더 가깝고, 작으면 물체가 더 멀리 있다는 것을 의미합니다.
fl = 2.043636363636363
"""기존 탄젠트 값"""
# tantheta = 0.7648732789907391
# tantheta = 0.6472684702
tantheta = 0.5884660658
# tantheta = 0.5296636614
# tantheta = 0.2944540438102669
img_width = 240
• 탄젠트 상수를 얻기 위해 여러 탄젠트를 시도해 봄.
• 기존 탄젠트값과 객체 간의 거리 30cm을 입력한 탄젠트 계산 코드에서 얻은 0.2944540438102669의 값을 2로 나누어 가장 실제 거리와 근사한 탄젠트 값을 찾음.
• 여러 반복 실행 결과 기존 탄젠트값이 아닌 0.5884660658 값이 실제와 가장 유사한 값을 보임.
• YOLO 모델은 객체 인식이 중요하므로 해상도가 높은 UXGA 해상도를 이용함.
시차를 계산 과정
1. 바운더리 박스 추출
• get_bounding_boxes(results) 함수는 YOLOv5 모델이 탐지한 객체의 바운더리 박스와 라벨을 추출합니다.
• boxes 배열은 이미지 내 객체의 위치를 나타내는 좌표값들로 구성됩니다.
• 각각의 box는 [x_min, y_min, x_max, y_max] 형태의 값을 가집니다. 이는 각각 객체의 좌측 상단 및 우측 하단의 좌표입니다.
# 바운더리 박스와 라벨을 가져오기
def get_bounding_boxes(results):
labels = results.xyxyn[0][:,-1].numpy()
boxes = results.xyxyn[0][:,:-1].numpy()
return labels, boxes
2. 시차 계산
• 시차(disparity)는 두 이미지에서 동일한 객체의 중심 위치 간의 차이로 계산됩니다.
• calculate_disparity(box1, box2, img_width) 함수는 다음의 과정을 통해 시차를 계산합니다:
# 시차를 계산하는 함수
def calculate_disparity(box1, box2, img_width):
center1 = (box1[0] + box1[2]) / 2 * img_width
center2 = (box2[0] + box2[2]) / 2 * img_width
disparity = abs(center1 - center2)
return disparity
객체의 중심 좌표 계산
box1 [0]과 box1 [2]은 첫 번째 이미지에서 객체의 좌측 상단과 우측 하단의 x 좌표입니다.
이 두 좌표를 더한 후 2로 나누면 객체의 중심 x 좌표를 구할 수 있습니다. 이 값에 이미지의 너비를 곱하여 실제 이미지 좌표로 변환합니다.
같은 방법으로 두 번째 이미지의 중심 좌표 center2도 계산됩니다.
시차 계산
두 이미지에서 동일 객체의 중심 좌표 간의 차이를 절댓값으로 계산하여 시차를 구합니다.
이 시차는 두 이미지 간의 거리(시차)이며, 이 값을 이용해 객체와 카메라 사이의 거리를 계산할 수 있습니다.
3. 거리 계산
• 시차를 이용해 calculate_distance(disparity, fl, tantheta, img_width) 함수에서 객체와 카메라 사이의 거리를 계산합니다.
• 계산된 시차(disparity)는 이 함수에 입력되며, 주어진 초점 거리(fl)와 tantheta 값을 이용해 거리를 계산합니다.
# 카메라와 객체 사이의 거리를 계산하는 함수
def calculate_distance(disparity, fl, tantheta, img_width):
distance = (7.05 / 2) * img_width * (1 / tantheta) / disparity + fl
return distance4. 시차 및 거리 출력
• 코드에서는 시차와 거리를 각각 터미널에 출력합니다.
• compute_distances_and_disparity 함수는 각 라벨에 대해 시차와 거리를 계산한 후 반환합니다.
# 같은 카테고리 객체 사이의 거리 및 시차 계산
def compute_distances_and_disparity(labels1, boxes1, labels2, boxes2, fl, tantheta, img_width):
distances = {}
disparities = {}
for i, label in enumerate(labels1):
if label in labels2:
j = np.where(labels2 == label)[0][0]
disparity = calculate_disparity(boxes1[i], boxes2[j], img_width)
distance = calculate_distance(disparity, fl, tantheta, img_width)
distances[label] = distance
disparities[label] = disparity
return distances, disparities#4. 이미지 분석 결과
아래 링크 필수 참조
스테레오 카메라 알고리즘 제작 | Notion
#1. CNN 이용 Depth Map 구현
udangtangtang-cording-oldcast1e.notion.site
'Python > [스테레오 비전]' 카테고리의 다른 글
| #6. 실시간 영상 분석 (0) | 2024.08.06 |
|---|---|
| #4. 스테레오 카메라 원리 분석(4) : Census transform와 Rank transform (1) | 2024.08.06 |
| #3. 스테레오 카메라 원리 분석(3) : SAD와 SSD (1) | 2024.08.06 |
| #2. 스테레오 카메라 원리 분석(2) : 스테레오 정합 (0) | 2024.08.06 |
| #1. 스테레오 카메라 원리 분석(1) : 스테레오 비전 (0) | 2024.08.06 |



