연결리스트를 이용한 집합 구현
아래 알고리즘에서 단일 연결리스트의 헤더노드는 값을 저장하는 유효 노드로서 작동한다.
집합 알고리즘의 구조체 선언
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int element;
typedef struct DListNode {
element data;
struct DListNode* next;
struct DListNode* prev;
}DListNode;
typedef struct SetType {
DListNode* H;
DListNode* T;
element N;
}SetType;| DListNode | SetType | ||||
| 멤버 | data | 집합의 데이터 저장 변수 | 멤버 | H | 헤드 노드 저장 |
| next | 다음 노드의 위치 저장 | T | 테일 노드 저장 | ||
| prev | 이전 노드의 위치 저장 | N | 노드의 개수 | ||
| 기능 | 연결리스트의 노드로 작동하며 3개로 구분됨 | 기능 | 연결리스트 노드를 포괄적으로 관리함. | ||
getNode 함수: 초기화된 임의의 노드 생성
① node라는 임의의 노드를 동적할당한다.
② node의 데이터 값을 0으로 초기화한다.
③ 위치 저장 구조체 포인터를 초기화한다.
DListNode* getNode(){
DListNode* node = (DListNode*)malloc(sizeof(DListNode));
node -> data = 0;
node ->next = NULL;
node ->prev = NULL;
return node;
}addNode함수: p 위치에 노드를 추가
① new라는 노드를 생성해 저장한다. getNode 함수를 이용한다.
② new노드에 데이터 값 e를 저장한다.
③ 생성한 new 노드와 인자로 받은 p 노드를 연결한다.
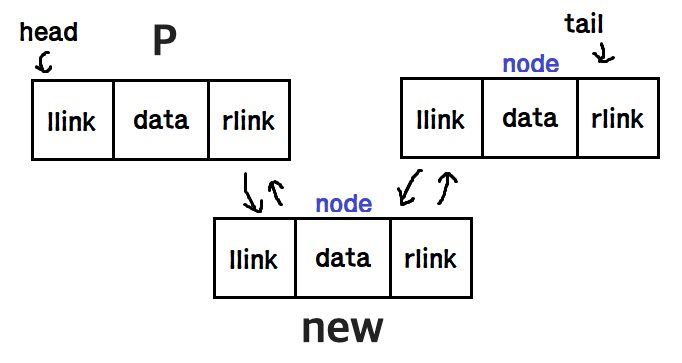
void addNode(SetType* S,DListNode* p, element e){
DListNode *new = getNode();
new ->data = e;
new->prev = p;
new->next = p->next;
p->next->prev = new;
p->next = new;
S->N ++;
}init 함수: 연결리스트 초기화 (SetType)
① 헤드 노드에 노드를 생성 후 저장
② 테일 노드에 노드를 생성 후 저장
③ 헤드 노드의 다음 노드를 테일 노드로 연결
④ 헤드 노드의 이전 노드를 헤드 노드로 연결
⑤ 노드의 개수를 0으로 초기화
void init(SetType* S) {
S->H = getNode();
S->T = getNode();
S->H ->next = S->T;
S->T->prev = S->H;
S->N = 0;
}add 함수: 연결리스트 추가
값을 정렬하여 추가하는 함수
① S의 헤드 노드에 접근하고 이를 p에 저장한다.
② 변수 status의 값을 1로 초기화한다.
③ p의 다음 노드가 테일 노드인 경우(노드가 하나도 없는 경우), S에 p노드를 추가한다.
④ p의 다음 노드가 테일 노드가 아닌 경우(노드가 하나 이상 존재),
⑤ e >= p->next->data && p->next->next!= NULL 조건을 만족하는 경우 반복
⑥ 인자로 받은 데이터 값이 p의 다음 노드 데이터와 같은 경우 status를 0으로 하고 반복을 종료한다.
⑦ p 다음 노드로 이동한다.
⑧ status 값이 1인 경우 노드를 추가한다.
void add(SetType* S, element e) {
DListNode* p = S->H;
int status = 1;
if(p->next == S->T) addNode(S,p,e);
else{
while(e >= p->next->data && p->next->next != NULL){
//입력된 원소의 값이 노드의 값보다 큰 경우
// = 노드를 순회하며 값을 저장해야함.
if(e == p->next->data) {status = 0;break;}
p = p->next;
}//값이 작거나, 마지막 노드보다 작거나, 값이 같거나
if(status == 1)addNode(S,p,e);
}
}add 함수에서 addNode 함수의 실행 조건은 아래와 같다.
| 1 | 노드가 하나도 없는 경우(H,T만 존재) | |
| 2 | 순회하고 있는 노드의 다음노드의 데이터 보다 크고 순회 중인 노드가 T의 이전 이전 노드보다 왼쪽인 경우 | 순회하고 있는 다음 노드의 데이터와 중복이 아닌 경우 |
· H와 T 노드만 있는 경우 노드는 무조건 추가된다.
· 노드가 한 개 이상 인 경우 위 표의 2번 조건을 만족해야만 노드가 추가된다. 이는 중복과 선형 오름차순을 위함이다.
· 아래 코드를 이용해 중복을 제거한다. 따라서 반복 횟수만큼 노드가 생성되지 않을 수 있다.
· 처음에 높은 수가 생성될 때, 낮은 숫자가 생성되면 while을 거치지 않고 노드가 추가될 수 있다. (while 조건에 부합하지 않음)
if(e == p->next->data) {status = 0;break;}addLast 함수: 후미에 연결리스트 추가
① new라는 노드를 생성해 저장한다. getNode 함수를 이용한다.
② new노드에 데이터를 저장한다.
③ S의 테일 노드에 접근하고 이를 p에 저장한다. 리스트의 후미에 노드를 추가하기 위함이다.
④ new->prev에 S->T ->prev를 연결한다.
⑤ S->T->prev->next 에 new를 연결한다.
⑦ S->T->prev에 new를 연결한다.
⑧ S의 노드 개수를 증가한다.

void addLast(SetType* S, element e){
DListNode* new = getNode();
new->data = e; // 새로운 노드에 값 저장
DListNode* p = S->T;
new->prev = S->T ->prev;
S->T->prev->next = new;
S->T->prev = new;
// printf("[%d]\n",new->data);
S->N++;
}
UnionSet 함수: 합집합 생성
① 반환할 리스트 S3를 생성하고 초기화한다.
② 합집합을 만들기 위해 인자로 받은 두 개의 리스트를 각각 p, q에 저장한다.
이때 NULL값으로 시작하는 것이 아니라, 노드만 사용한다. (S->H->next)
③ p와 q가 모두 NULL이 아닐 때까지 반복한다.
④ p의 요소가 q의 요소보다 큰 경우 p의 요소를 합집합에 추가하고 p를 다음 노드로 보낸다.
⑤ q의 요소가 p의 요소보다 큰 경우 q의 요소를 합집합에 추가하고 q를 다음 노드로 보낸다.
⑤ p의 요소와 q의 요가 같은 경우 p 또는 q의 요소를 합집합에 추가하고 p와 q를 다음 노드로 보낸다.
⑦ 남은 원소를 추가한다.
⑧ 합집합 S3를 반환한다.
SetType UnionSet(SetType* S1, SetType* S2) {
SetType S3;
init(&S3);
DListNode* p = S1->H->next;
DListNode* q = S2->H->next;
while (p != S1->T && q != S2->T) {
if (p->data < q->data) {
addLast(&S3, p->data);
p = p->next;
} else if (p->data > q->data) {
addLast(&S3, q->data);
q = q->next;
} else { // 두 집합에 모두 존재하는 원소인 경우
addLast(&S3, p->data);
p = p->next;
q = q->next;
}
}
// 남은 원소들 추가
while (p != S1->T) {
addLast(&S3, p->data);
p = p->next;
}
while (q != S2->T) {
addLast(&S3, q->data);
q = q->next;
}
return S3;
}IntersectSet 함수: 교집합 생성
① 반환할 리스트 S3를 생성하고 초기화한다.
② 교집합을 만들기 위해 인자로 받은 두 개의 리스트를 각각 p, q에 저장한다.
이때 NULL값으로 시작하는 것이 아니라, 노드만 사용한다. (S->H->next)
③ p와 q가 모두 NULL이 아닐 때까지 반복한다.
④ p의 요소가 q의 요소보다 큰 경우 q를 다음 노드로 보낸다.
⑤ q의 요소가 p의 요소보다 큰 경우 p를 다음 노드로 보낸다.
⑤ p의 요소와 q의 요가 같은 경우 p 또는 q의 요소를 합집합에 추가하고 p와 q를 다음 노드로 보낸다.
⑦ 교집합은 하나의 집합이 종료되면 더 이상 순회할 필요가 없다.
⑧ 교집합 S3를 반환한다.
두 리스트 중 하나의 값이 더 큰 경우(두 리스트의 값이 다른 경우),
작은 쪽을 크게하여 같은 값을 찾는다.
SetType IntersectSet(SetType* S1, SetType* S2) {
SetType S3;
init(&S3);
DListNode* p = S1->H->next;
DListNode* q = S2->H->next;
while (p != S1->T && q != S2->T) {
if (p->data < q->data) {
p = p->next;
} else if (p->data > q->data) {
q = q->next;
} else {
addLast(&S3, p->data);
p = p->next;
q = q->next;
}
}
return S3;
}DifferenceSet 함수: 차집합 생성
① 반환할 리스트 S3를 생성하고 초기화한다.
② 인자로 받은 S1에 S2의 요소를 제거한 차집합을 구하기 위해 p에 S1->H->next를 저장한다.
③ p가 NULL이 아닐 때까지 반복한다.
④ p의 요소가 q의 요소보다 큰 경우 q를 다음 노드로 보낸다.
⑤ p의 요소가 S2에 존재하면, 차집합에 추가한다.
⑤ p의 요소가 S2에 존재하지 않으면, 다음 노드로 넘어간다.
⑦ 차집합 S3를 반환한다.
//차집합
SetType DifferenceSet(SetType* S1, SetType* S2) {
SetType S3;
init(&S3);
DListNode* p = S1->H->next;
while (p != S1->T) {
if (!isMember(S2, p->data)) {
addLast(&S3, p->data);
}
p = p->next;
}
return S3;
}isMember 함수: 집합 요소 확인
① 임의의 노드 p를 생성한다.
② p = S->H->next부터 p->next!= NULL일 때까지 p = p->next를 저장한다.
③ 인자로 받은 요소 e가 집합에 존재하면 1을 반환한다.
④ 조건문을 만족하지 못한 경우 0을 반환한다.
int isMember(SetType* S, element e){
DListNode* p;
for (p = S->H->next; p->next != NULL; p = p->next) {
if(p->data == e) return 1;
}
return 0;
}traverse 함수: 순회 및 출력 함수
void traverse(SetType* S){
DListNode* p;
for (p = S->H->next; p->next != NULL; p = p->next) {
printf("[%d] <=> ", p->data);
}printf("\b\b\b\b \n");
}
main 함수
void lineprint(){printf("------------------------------------------------------------------------------------------------------------------------\n");}
int main(){
SetType A,B;
init(&A);init(&B);
srand(time(NULL));
for(int i=0;i<7;i++){
int e1 = rand() % 10 +1;
int e2 = rand() % 10 +1;
add(&A,e1);
add(&B,e2);
} lineprint();
printf("A : "); traverse(&A);
printf("B : "); traverse(&B); lineprint();
SetType union_ = UnionSet(&A,&B);
printf("union : ");
traverse(&union_);lineprint();
SetType intersection; init(&intersection);
intersection = IntersectSet(&A,&B);
printf("intersection : "); traverse(&intersection);
lineprint();
SetType differenceAB = DifferenceSet(&A,&B);
printf("difference(AB) : "); traverse(&differenceAB);
SetType differenceBA = DifferenceSet(&B,&A);
printf("difference(BA) : "); traverse(&differenceBA); lineprint();
}전체 코드
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int element;
typedef struct DListNode {
element data;
struct DListNode* next;
struct DListNode* prev;
}DListNode;
typedef struct SetType {
DListNode* H;
DListNode* T;
element N;
}SetType;
DListNode* getNode(){
DListNode* node = (DListNode*)malloc(sizeof(DListNode));
node -> data = 0;
node ->next = NULL;
node ->prev = NULL;
return node;
}
void addNode(SetType* S,DListNode* p, element e){
DListNode *new = getNode();
new ->data = e;
new->prev = p;
new->next = p->next;
p->next->prev = new;
p->next = new;
S->N ++;
}
int isMember(SetType* S, element e){
DListNode* p;
for (p = S->H->next; p->next != NULL; p = p->next) {
if(p->data == e) return 1;
}
return 0;
}
void init(SetType* S) {
S->H = getNode();
S->T = getNode();
S->H ->next = S->T;
S->T->prev = S->H;
S->N = 0;
}
void add(SetType* S, element e) {
DListNode* p = S->H;
int status = 1;
if(p->next == S->T) addNode(S,p,e);
else{
while(e >= p->next->data && p->next->next != NULL){
/*
인자로 받은 값이 p->next의 노드보다 큰 경우 : 작은 순서대로 정렬 (중복 배제 전)
p->next->next != NULL인경우
*/
//입력된 원소의 값이 노드의 값보다 큰 경우
// = 노드를 순회하며 값을 저장해야함.
if(e == p->next->data) {status = 0;break;}
p = p->next;
}//값이 작거나, 마지막 노드보다 작거나, 값이 같거나
if(status == 1)addNode(S,p,e);
}
}
void addLast(SetType* S, element e){
DListNode* new = getNode();
new->data = e; // 새로운 노드에 값 저장
DListNode* p = S->T;
new->prev = S->T ->prev;
new->next = S->T;
S->T->prev->next = new;
S->T->prev = new;
// printf("[%d]\n",new->data);
S->N++;
}
SetType UnionSet(SetType* S1, SetType* S2) {
SetType S3;
init(&S3);
DListNode* p = S1->H->next;
DListNode* q = S2->H->next;
while (p != S1->T && q != S2->T) {
if (p->data < q->data) {
addLast(&S3, p->data);
p = p->next;
} else if (p->data > q->data) {
addLast(&S3, q->data);
q = q->next;
} else { // 두 집합에 모두 존재하는 원소인 경우
addLast(&S3, p->data);
p = p->next;
q = q->next;
}
}
// 남은 원소들 추가
while (p != S1->T) {
addLast(&S3, p->data);
p = p->next;
}
while (q != S2->T) {
addLast(&S3, q->data);
q = q->next;
}
return S3;
}
/*교집합*/
SetType IntersectSet(SetType* S1, SetType* S2) {
SetType S3;
init(&S3);
DListNode* p = S1->H->next;
DListNode* q = S2->H->next;
while (p != S1->T && q != S2->T) {
if (p->data < q->data) {
p = p->next;
} else if (p->data > q->data) {
q = q->next;
} else {
addLast(&S3, p->data);
p = p->next;
q = q->next;
}
}
return S3;
}
//차집합
SetType DifferenceSet(SetType* S1, SetType* S2) {
SetType S3;
init(&S3);
DListNode* p = S1->H->next;
while (p != S1->T) {
if (!isMember(S2, p->data)) {
addLast(&S3, p->data);
}
p = p->next;
}
return S3;
}
void traverse(SetType* S){
DListNode* p;
for (p = S->H->next; p->next != NULL; p = p->next) {
printf("[%d] <=> ", p->data);
}printf("\b\b\b\b \n");
}
void lineprint(){
printf("------------------------------------------------------------------------------------------------------------------------\n");
}
int main(){
SetType A,B;
init(&A);init(&B);
srand(time(NULL));
for(int i=0;i<7;i++){
int e1 = rand() % 10 +1;
int e2 = rand() % 10 +1;
add(&A,e1);
add(&B,e2);
} lineprint();
printf("A : "); traverse(&A);
printf("B : "); traverse(&B); lineprint();
SetType union_ = UnionSet(&A,&B);
printf("union : ");
traverse(&union_);lineprint();
SetType intersection; init(&intersection);
intersection = IntersectSet(&A,&B);
printf("intersection : "); traverse(&intersection);
lineprint();
SetType differenceAB = DifferenceSet(&A,&B);
printf("difference(AB) : "); traverse(&differenceAB);
SetType differenceBA = DifferenceSet(&B,&A);
printf("difference(BA) : "); traverse(&differenceBA); lineprint();
}'Datastructure > [5] 집합' 카테고리의 다른 글
| [5] 집합 ① 배열을 이용한 집합 구현 (0) | 2024.04.06 |
|---|
