단일 연결리스트의 특징
배열과 단일 연결리스트는 하나 이상의 데이터를 저장하는 면에서 기본 개념에서 배열과 거의 같다. 그렇다면 배열을 사용하지 않고 연결리스트를 사용하는 이유는 무엇일까. 단일 연결리스트의 장점은 다음과 같다.
단일 연결리스트의 장점은 배열의 단점과 같다.
배열은 연속적인 데이터를 저장하며 같은 자료형을 갖는 데이터의 집합이다. 이때 배열은 생성할 때 데이터를 저장하는데 필요한 모든 메모리를 한번 확보해 사용한다. 따라서 프로그램이 실행되는 중간에 배열을 크기를 바꿀 수 없다. 즉, 배열 안에 저장되어 있는 값들을 정렬할 때에도 메모리에 저장된 있는 각각의 값을 바꿔야 하는 것이다.
단일 연결리스트는 이러한 배열의 단점을 해결한다.
배열은 연속된 메모리를 사용하며 총 메모리가 고정되어 크기를 바꿀 수 없지만 연결리스트는 서로 반드시 연속적인 관계가 아닌, 연속적이지 않은 데이터를 링크로 연결하는 개념이다.
연결리스트는 서로 반드시 연속적인 관계가 아닌, 연속적이지 않은 데이터를 링크로 연결하는 개념
단일 연결리스트의 삽입 알고리즘
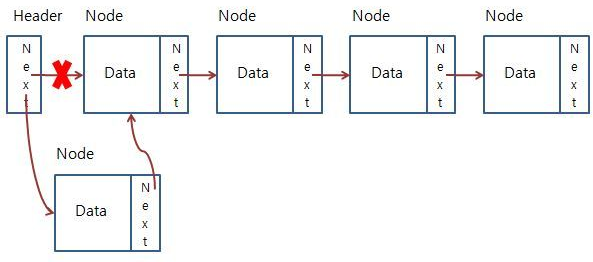
위의 사진에서 기존의 노드를 각각 A,B,C,D라고 하고 추가되는 노드를 X라고 하자.
새로운 노드를 추가하는 기본적인 알고리즘을 설명하면 다음과 같다.
- 헤드 노드의 연결 방향을 A에서 X로 바꾼다.
- X 노드의 연결방향을 A로 선언한다.
해당 방식으로 노드를 추가하면 A -> B -> C -> D에서 X가 추가되어 X -> A -> B -> C -> D가 된다.
만약 배열에서 새로운 값을 추가하려면 추가할 인덱스 뒤의 모든 요소값이 한 칸씩 뒤로 이동해야 한다. 이 과정에서 불필요한 연산이 발생하고 맨 마지막에 값을 저장할 공간이 추가로 있어야 한다. 이러한 문제점을 단일 연결리스트는 동적할당을 통해 필요할 때 원하는 자료형에 맞는 크기의 메모리를 할당하고 연결하는 작업을 통해 해결할 수 있다.
이제 실제 연결리스트를 작성해보자. 코드는 다음과 같다.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef int element;
typedef struct ListNode {
element data;
struct ListNode *next;
}ListNode;
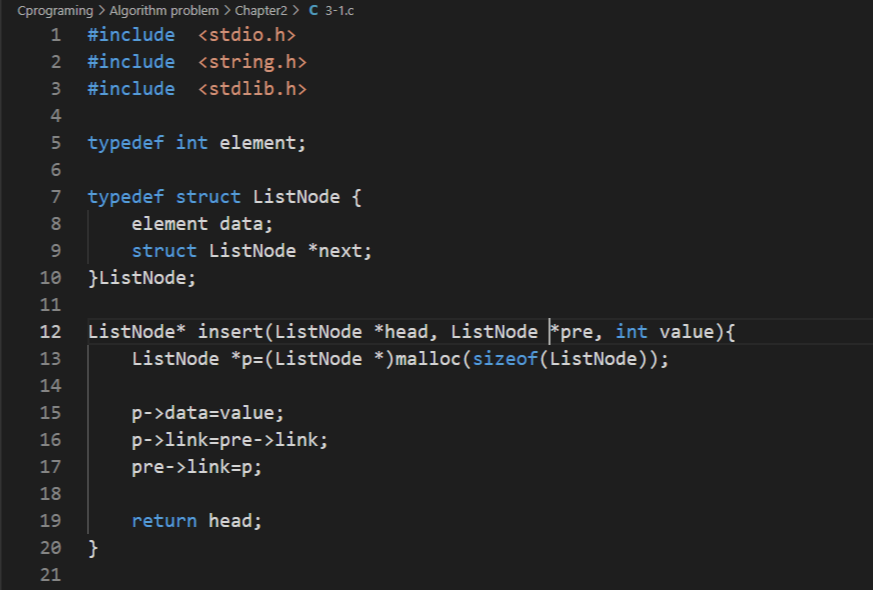
ListNode* insert(ListNode *head, ListNode *pre, int value){
ListNode *p=(ListNode *)malloc(sizeof(ListNode));
p->data=value;
p->next=pre->next;
pre->next=p;
return head;
}
int main(){
/*노드를 메모리 동적 할당으로 생성하기*/
ListNode* head = (ListNode*)malloc(sizeof(ListNode)); //헤드 노드 생성
head->next = NULL;
ListNode* ListNode1 = (ListNode*)malloc(sizeof(ListNode)); //node1 이라는 새로운 노드를 새로 할당
/*머리노드와 node1을 연결하기*/
ListNode1->next = head->next;//node1의 꼬리를 (기존)헤드의 꼬리로 연결
ListNode1->data = 10;//node1의 데이터 업데이드
head->next = ListNode1;//헤드의 꼬리를 node1으로 업데이트
ListNode* curr = head->next; //순회용 노드 생성
while(curr != NULL){ //연결리스트 출력
printf("%d\n", curr->data);
curr = curr->next;
}
free(head);
free(ListNode1);
return 0;
}코드 설명
[Code] 5 - 10
typedef int element;
typedef struct ListNode {
element data;
struct ListNode *next;
}ListNode;- int 형 자료형을 element로 정의한다.
- 연결리스트를 선언한다. 이때 자료형은 element(int) 형이고 자기 참조를 통해 다음 노드를 지정한다.
- next는 다음 노드의 주소를 저장할 자기참조 구조체포인터이다.
- ListNode라는 연결리스트를 선언한다.
[Code] 12 - 20
ListNode* insert(ListNode *head, ListNode *pre, int value){
ListNode *p=(ListNode *)malloc(sizeof(ListNode));
p->data=value;
p->next=pre->next;
pre->next=p;
return head;
}새로운 노드를 추가하는 노드 추가 함수로, 다음 챕터에서 자세히 다루도록 한다. 기본적인 로직은 다음과 같다.
1. 기본적으로 인자로 받은 연결리스트의 자료형과 크기에 맞는 연결리스트를 동적할당으로 통해 생성한다.
2. 인자로 받은 새로운 데이터를 저장하여 연결하고 싶은 연결리스트의 처음과 끝에 연결한다.
3. 마지막으로 연결리스트의 헤드 주소를 반환한다.

[Code] 24 - 26
ListNode* head = (ListNode*)malloc(sizeof(ListNode)); //헤드 노드 생성
head->next = NULL;
ListNode* ListNode1 = (ListNode*)malloc(sizeof(ListNode)); //node1 이라는 새로운 노드를 새로 할당- ListNode의 형식을 가진 head 연결리스트(헤드 노드)를 동적할당하여 생성한다.
- 처음 생성한 헤드 노드이므로 다음 연결방향으로 null로 초기화한다.
- ListNode1이라는 새로운 노드를 새로 할당한다.
[Code] 30 - 32
/*머리노드와 node1을 연결하기*/
ListNode1->next = head->next;//node1의 꼬리를 (기존)헤드의 꼬리로 연결
ListNode1->data = 10;//node1의 데이터 업데이드
head->next = ListNode1;//헤드의 꼬리를 node1으로 업데이트새로 추가한 노드의 값을 저장하고 시작과 끝을 지정한다.
[Code] 34 - 38
ListNode* curr = head->next; //순회용 노드 생성
while(curr != NULL){ //연결리스트 출력
printf("%d\n", curr->data);
curr = curr->next;
}- 연결리스트의 값을 확인할 수 있도록 새로운 노드를 생성한다. 이때 따로 동적할당을 하지 않는 이유는 새로운 노드를 추가할 때에는 노드의 시작과 끝의 주소를 알 수 있도록 생성해야 하고 이 과정에서 구조체를 이용하지만 순회용 노드는 노드의 시작점만 알면 되기 때문에 ListNode를 참조하여 노드만 생성한다.\
- 순회용 노드를 생성했다면 연결리스트의 시작과 연결하고 출력한다. 출력 후에는 다음 노드로 변환한다.
- 이를 노드의 값이 null(노드에 저장된 값이 없음)이 나올 때까지 반복한다. 시작과 끝의 노드에는 값이 없으므로 마지막 노드로 이동하면 반복이 종료된다.
위의 알고리즘을 응용하면 새로운 노드를 여러 개 추가하고 출력할 수 있다.
다음 포스팅에서는 연결리스트의 생성과 삭제 알고리즘에 대해 배워보자.
'Datastructure > [Problem]' 카테고리의 다른 글
| #2-3. 연결 리스트의 삽입과 삭제(1) : 삽입 (0) | 2023.09.06 |
|---|---|
| #2-3. 연결 리스트의 삽입과 삭제: 이중 연결 리스트를 곁들인,, (1) | 2023.09.05 |
| #2-1. 연결 리스트 (0) | 2023.09.04 |
| #1-6. 포인터의 활용 (0) | 2023.09.04 |
| #1-5. 포인터 배열과 포인터 연산 (0) | 2023.09.03 |



