4주차: 모델 훈련
머신러닝 모델 훈련에 대한 이해
머신러닝 모델 훈련은 데이터에서 패턴을 학습하고, 이를 바탕으로 새로운 데이터에 대한 예측을 수행하는 중요한 과정이다. 이번 글에서는 머신러닝 모델 훈련에 사용되는 다양한 방법을 다루고, 그 과정에서 필요한 핵심 개념들을 정리한다.
1. 선형 회귀 (Linear Regression)
선형 회귀는 가장 기본적인 회귀 분석 기법 중 하나로, 주어진 데이터에 가장 적합한 직선을 찾아 예측을 수행하는 방법이다. 선형 회귀는 아래와 같은 수식으로 표현할 수 있다.
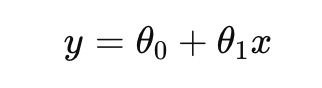
이때, 비용 함수(Cost Function)를 최소화하기 위해 경사 하강법(Gradient Descent)을 이용할 수 있다. 비용 함수는 주로 평균 제곱 오차(MSE, Mean Squared Error)로 측정된다.
파이썬을 사용하여 선형 회귀를 구현하는 방법은 다음과 같다.
import numpy as np
from sklearn.linear_model import LinearRegression
# 랜덤 데이터 생성
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 선형 회귀 모델 훈련
lin_reg = LinearRegression()
lin_reg.fit(X, y)
# 예측 수행
X_new = np.array([[0], [2]])
y_predict = lin_reg.predict(X_new)
print(y_predict)4.1.1 정규 방정식 (Normal Equation)
정규 방정식은 선형 회귀 문제를 푸는 간단한 방법 중 하나로, 경사 하강법을 사용하지 않고 직접적으로 최적의 파라미터 값을 계산한다. 이 방식은 다음 수식으로 표현된다:

여기서 는 입력 데이터의 행렬이고, 는 타겟 벡터이다. 이 식을 사용하면 경사 하강법과 달리 반복적인 학습 없이 한 번의 계산으로 최적의 모델 파라미터 θ\theta를 구할 수 있다.
계산 과정
1. 먼저 행렬을 준비한다는 기존의 입력 데이터 에 편향 항을 추가한 것이다.
2. 이후 를 계산한 후, 이를 와 곱해 최적의 파라미터 를 구한다.
예측 결과
구한 를 사용해 새로운 데이터를 예측할 수 있다.
X_new = np.array([[0], [2]])
X_new_b = np.c_[np.ones((2, 1)), X_new]
y_predict = X_new_b.dot(theta_best)
print("예측 결과:", y_predict)4.1.2 계산 복잡도
정규 방정식의 계산 복잡도는 다음과 같다:
- 행렬 의 역행렬을 구하는 데 의 시간이 소요된다.
- 이 방식은 입력 데이터가 작을 때는 적합하지만, 데이터가 많아지면 매우 비효율적이다. 특히 샘플 개수 이 클수록 계산 비용이 기하급수적으로 증가한다.
- 정규 방정식은 데이터가 수만 개 이하일 때는 적합하지만, 그 이상일 경우 경사 하강법 등의 다른 방법이 더 효율적이다
하강법의 비교
| 방법 | 장점 | 단점 | 계산 복잡도 |
| 정규 방정식 | 반복이 필요 없고 직접적인 해결 가능 | 데이터가 클 경우 비효율적 | O(n^3) |
| 배치 경사 하강법 | 데이터가 클 경우에도 사용 가능 | 반복적 계산 필요, 학습률 설정이 중요 | |
| 확률적 경사 하강법 | 빠른 수렴, 대규모 데이터 처리에 적합 | 최적 값에 도달하지 않고 진동 가능 | |
| 미니배치 경사 하강법 | 확률적 경사 하강법보다 안정적, 더 빠름 | 여전히 학습률과 배치 크기 선택이 중요 |
선형 데이터 시각화
다음은 선형 데이터를 시각화한 그래프이다. 회귀선이 데이터에 얼마나 잘 맞는지를 직관적으로 보여준다.
import matplotlib.pyplot as plt
# 데이터와 예측 결과 시각화
plt.plot(X_new, y_predict, "r-", label="Predictions")
plt.plot(X, y, "b.")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.show()2. 경사 하강법 (Gradient Descent)
경사 하강법은 비용 함수를 최소화하기 위해 반복적으로 파라미터를 업데이트하는 알고리즘이다. 이는 대규모 데이터셋에 적합하며, 선형 회귀뿐만 아니라 다양한 머신러닝 모델에서 사용된다. 경사 하강법의 기본 개념은 현재 위치에서의 기울기를 계산한 후, 이 기울기의 반대 방향으로 일정한 비율(학습률, eta)을 이동하는 것이다.
경사 하강법을 활용한 선형 회귀는 다음과 같이 구현할 수 있다.
eta = 0.1 # 학습률
n_iterations = 1000 # 반복 횟수
m = 100 # 데이터 개수
theta = np.random.randn(2, 1) # 무작위 초기화
for iteration in range(n_iterations):
gradients = 2 / m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients2.1 경사 하강법의 원리
경사 하강법의 기본 원리는 비용 함수의 기울기를 계산해 파라미터를 조정함으로써 최적화 문제를 푸는 것이다. 비용 함수가 최소값에 도달할 때까지 기울기 방향으로 계속 이동하면서 파라미터를 업데이트한다. 비용 함수는 주로 MSE(Mean Squared Error, 평균 제곱 오차)로 측정된다.
비용 함수 에 대한 경사 하강법의 수식은 다음과 같다.
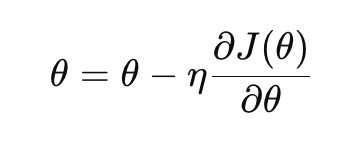
여기서:
- 는 모델 파라미터
- 는 학습률(learning rate)
- 는 비용 함수의 기울기
2.2 경사 하강법의 종류
- 배치 경사 하강법 (Batch Gradient Descent): 모든 훈련 데이터를 사용해 한 번의 업데이트를 수행한다. 이 방법은 정확하지만 대규모 데이터셋에서는 비효율적이다.
- 확률적 경사 하강법 (Stochastic Gradient Descent, SGD): 각 샘플을 사용해 매번 업데이트를 수행하며, 계산 속도가 빠르지만 진동이 발생할 수 있다.
- 미니배치 경사 하강법 (Mini-batch Gradient Descent): 데이터를 작은 배치로 나누어 각각에 대해 경사 하강법을 적용하는 방식이다. 배치 경사 하강법과 SGD의 절충점이다.
2.3 파이썬 코드 구현
배치 경사 하강법
import numpy as np
# 데이터 생성
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 편향 추가
X_b = np.c_[np.ones((100, 1)), X]
# 학습률과 반복 횟수
eta = 0.1
n_iterations = 1000
m = 100
# 파라미터 초기화
theta = np.random.randn(2, 1)
# 배치 경사 하강법
for iteration in range(n_iterations):
gradients = 2 / m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
print("Theta:", theta)확률적 경사 하강법 (SGD)
from sklearn.linear_model import SGDRegressor
# 모델 학습
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.01, random_state=42)
sgd_reg.fit(X, y.ravel())
print("Intercept:", sgd_reg.intercept_)
print("Coef:", sgd_reg.coef_)미니배치 경사 하강법
import numpy as np
# 데이터 생성
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
# 학습률과 반복 횟수
eta = 0.1
n_iterations = 1000
minibatch_size = 20
m = len(X_b)
# 파라미터 초기화
theta = np.random.randn(2, 1)
# 미니배치 경사 하강법
for iteration in range(n_iterations):
minibatch_indices = np.random.randint(m, size=minibatch_size)
X_mini = X_b[minibatch_indices]
y_mini = y[minibatch_indices]
gradients = 2 / minibatch_size * X_mini.T.dot(X_mini.dot(theta) - y_mini)
theta = theta - eta * gradients
print("Theta:", theta)2.4 경사 하강법 비교
| 방법 | 장점 | 단점 | 계산 복잡도 |
| 배치 경사 하강법 | 수렴 시 정확함 | 데이터가 클 경우 비효율적 | |
| 확률적 경사 하강법 | 빠르게 수렴, 대규모 데이터 처리에 적합 | 수렴 속도가 느리며 최적 값에 진동 가능 | |
| 미니배치 경사 하강법 | 성능과 속도의 균형, 안정적인 수렴 | 여전히 학습률과 배치 크기 선택이 중요 |
2.5 계산 복잡도 분석
경사 하강법의 계산 복잡도는 사용하는 방법에 따라 달라지지만, 대략적인 계산 복잡도는 다음과 같다.
· 배치 경사 하강법: (샘플 개수와 특성 수의 곱)
· 확률적 경사 하강법: (샘플 개수에 비례)
· 미니배치 경사 하강법: 배치 크기와 데이터 크기에 따라
3. 확률적 경사 하강법 (Stochastic Gradient Descent)
확률적 경사 하강법(SGD)은 모델을 훈련할 때 전체 데이터셋을 한 번에 사용하는 대신, 각 샘플을 하나씩 사용해 매번 모델 파라미터를 업데이트하는 방법이다. 이는 전체 데이터셋을 사용하는 배치 경사 하강법(Batch Gradient Descent)과는 차별화된 점이다.
3.1 확률적 경사 하강법의 개요
SGD는 매 반복마다 무작위로 선택된 단일 샘플을 사용하여 파라미터를 업데이트한다. 이를 통해 SGD는 매우 큰 데이터셋에 대해서도 빠르게 수렴할 수 있는 장점이 있다. 하지만, 무작위 샘플 선택으로 인해 SGD는 최적 해에 수렴하는 과정에서 진동이 발생할 수 있으며, 최적 해 주변에서 오락가락하는 경우가 발생할 수 있다.
3.2 확률적 경사 하강법의 수식
확률적 경사 하강법에서 파라미터 는 다음과 같이 업데이트된다:

· 는 학습률(learning rate)이다.
는 하나의 샘플 x^{(i)}, y^{(i)}에 대한 비용 함수의 기울기이다.
3.3 확률적 경사 하강법의 장점과 단점
| 장점 | 단점 |
|
|
3.4 확률적 경사 하강법의 파이썬 구현
다음은 파이썬으로 확률적 경사 하강법을 구현한 코드 예시이다.
import numpy as np
from sklearn.linear_model import SGDRegressor
# 데이터 생성
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# SGDRegressor 모델 생성 및 훈련
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.01, random_state=42)
sgd_reg.fit(X, y.ravel())
# 모델 예측
print("Intercept:", sgd_reg.intercept_)
print("Coefficients:", sgd_reg.coef_)3.5 학습률과 수렴
학습률 η는 확률적 경사 하강법의 중요한 요소이다. 학습률이 너무 크면 모델이 최적 해를 넘어서 진동하거나 발산할 수 있으며, 학습률이 너무 작으면 수렴 속도가 매우 느려질 수 있다. 일반적으로 학습률을 동적으로 조정하는 방법(learning rate decay)을 사용하여 초기에는 빠르게 학습하고, 나중에는 수렴 속도를 높인다.
from sklearn.linear_model import SGDRegressor
# 학습률 조정과 함께 SGD 사용
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.01, learning_rate='adaptive', random_state=42)
sgd_reg.fit(X, y.ravel())
이 코드에서는 learning_rate='adaptive'를 설정하여 학습률이 자동으로 조정되도록 한다.
3.6 확률적 경사 하강법의 계산 복잡도
확률적 경사 하강법은 각 샘플에 대해 기울기를 계산하므로, 배치 경사 하강법에 비해 계산 복잡도가 매우 낮다. 데이터셋이 커질수록 배치 경사 하강법은 계산량이 기하급수적으로 증가하지만, 확률적 경사 하강법은 샘플 단위로 파라미터를 업데이트하므로 처리 속도가 매우 빠르다.
3.7 확률적 경사 하강법의 적용 사례
확률적 경사 하강법은 대규모 데이터셋을 다룰 때 특히 유리하며, 실시간 학습이 필요한 시스템에도 적용될 수 있다. 또한, 추천 시스템, 온라인 광고 등 실시간으로 빠르게 반응해야 하는 분야에서 주로 사용된다.
4. 다항 회귀 (Polynomial Regression)
선형 회귀는 데이터가 직선 형태로 분포되어 있을 때 적합하지만, 실제 데이터는 종종 비선형성을 띤다. 이를 해결하기 위해 다항 회귀를 사용할 수 있으며, 입력 특성을 다항식 형태로 확장하여 더 복잡한 관계를 모델링한다. 다항 회귀는 선형 회귀와 마찬가지로 학습이 가능하지만, 데이터의 차원을 증가시켜 비선형성을 반영하는 방식이다.
다음은 2차 다항 회귀를 적용한 코드이다.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
print(lin_reg.intercept_, lin_reg.coef_)4.1 개요
다항 회귀는 데이터를 선형 관계가 아닌 다항식 형태로 모델링하는 기법이다. 선형 회귀는 데이터의 직선적 패턴을 찾는 반면, 다항 회귀는 데이터를 더 복잡한 비선형 관계로 설명할 수 있다. 다항 회귀는 데이터를 다항식 형태로 변환하여 선형 회귀를 적용하는 방식으로 비선형 데이터를 모델링하는 데 사용된다.
4.2 다항식 특성 추가
다항 회귀는 데이터를 단순히 곱하거나 더하는 것이 아닌, 데이터를 비선형적으로 변환하여 모델을 더욱 유연하게 만든다. 예를 들어, 단순한 선형 특성 xx는 다음과 같은 다항식 특성으로 변환될 수 있다.

4.3 파이썬을 이용한 다항 회귀 구현
다음은 파이썬을 사용하여 다항 회귀를 구현하는 코드이다. PolynomialFeatures를 사용해 입력 데이터의 다항식 특성을 추가하고, 이를 기반으로 선형 회귀 모델을 학습한다.
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 데이터 생성
np.random.seed(42)
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5 * X**2 + X + 2 + np.random.randn(m, 1)
# 다항식 특성 추가
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
# 선형 회귀 모델 학습
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
# 예측
X_new = np.linspace(-3, 3, 100).reshape(100, 1)
X_new_poly = poly_features.transform(X_new)
y_new = lin_reg.predict(X_new_poly)
# 결과 시각화
plt.plot(X_new, y_new, "r-", linewidth=2, label="Predictions")
plt.plot(X, y, "b.", label="Data")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.show()이 코드는 2차 다항 회귀를 적용한 예시이다. PolynomialFeatures를 사용하여 데이터의 2차 항을 추가한 후, 이를 선형 회귀 모델에 적용해 예측을 수행한다.
4.4 다항 회귀의 한계
다항 회귀는 데이터의 복잡한 패턴을 모델링할 수 있다는 장점이 있지만, 과적합(Overfitting)의 위험이 있다. 모델이 너무 복잡해지면 학습 데이터에 과도하게 적합하게 되어, 새로운 데이터에 대해 잘 일반화되지 않는 문제가 발생할 수 있다.
이를 방지하기 위해 적절한 차수(degree)를 선택하고, 정규화 기법을 함께 사용하는 것이 중요하다.
4.5 모델 평가
다항 회귀 모델을 평가할 때는 교차 검증(Cross-validation)이나 학습 곡선(Learning Curve)을 사용하여 과적합을 방지하고, 모델의 성능을 객관적으로 평가할 수 있다.
5. 정규화 기법 (Ridge, Lasso, ElasticNet)
정규화 기법은 머신러닝 모델에서 과적합을 방지하기 위해 사용되는 중요한 기법이다. 과적합은 모델이 훈련 데이터에 과도하게 적합하여 새로운 데이터에 대해 일반화 능력이 떨어지는 문제를 말한다. 이를 해결하기 위해 모델의 복잡도를 제어하고 불필요한 특성의 영향을 줄이기 위한 정규화 기법을 사용한다. 이 장에서는 대표적인 정규화 기법인 Ridge 회귀, Lasso 회귀, ElasticNet을 소개한다.
- Ridge 회귀: 비용 함수에 정규화 항을 추가하여 과적합을 방지한다.
- Lasso 회귀: Ridge와 유사하지만, 일부 특성의 가중치를 0으로 만들어 불필요한 특성을 제거하는 역할을 한다.
- ElasticNet: Ridge와 Lasso의 혼합형으로, 두 방식의 장점을 결합한 기법이다.
5.1 Ridge 회귀 (Ridge Regression)
Ridge 회귀는 비용 함수에 정규화 항을 추가하여 모델의 가중치가 지나치게 커지는 것을 방지하는 기법이다. L2 정규화라고도 불리며, 비용 함수는 다음과 같이 정의된다.

여기서 는 정규화 강도를 조절하는 하이퍼파라미터이다. 값이 클수록 모델의 복잡성이 줄어들고, 작은 값은 기존 선형 회귀와 비슷해진다.
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky")
ridge_reg.fit(X, y)
print(ridge_reg.predict([[1.5]]))5.2 Lasso 회귀 (Lasso Regression)
Lasso 회귀는 L1 정규화를 적용한 방법으로, 비용 함수에 절대값 항을 추가한다. Ridge 회귀와 달리 Lasso는 불필요한 특성의 가중치를 0으로 만들어 자동으로 특성 선택을 수행하는 효과가 있다.
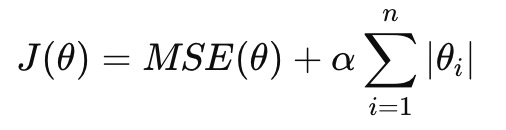
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
print(lasso_reg.predict([[1.5]]))5.3 ElasticNet
ElasticNet은 Ridge와 Lasso의 장점을 결합한 방법이다. L1과 L2 정규화를 모두 적용하여 복잡한 데이터셋에 더욱 효과적으로 대응할 수 있다. ElasticNet은 다음과 같은 비용 함수로 정의된다.

여기서 은 Lasso와 Ridge의 혼합 비율을 결정하는 하이퍼파라미터이다.
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X, y)
print(elastic_net.predict([[1.5]]))정규화 기법 비교
| 기법 | 장점 | 단점 | 특성 선택 효과 |
| Ridge 회귀 | 과적합 방지, L2 정규화 적용 | 중요한 특성을 제거하지 않음 | 없음 |
| Lasso 회귀 | 불필요한 특성을 자동으로 제거 | 데이터가 많을 경우 성능 저하 가능 | 있음 |
| ElasticNet | Ridge와 Lasso의 장점 결합, 유연한 정규화 | 하이퍼파라미터 조정 필요 | 있음 |
4.6 모델 평가 및 선택
모델을 훈련한 후, 그 성능을 평가하는 것은 매우 중요하다. 평가를 통해 모델이 얼마나 정확하게 예측할 수 있는지, 그리고 과적합(overfitting)이나 과소적합(underfitting) 문제를 방지할 수 있는지 판단할 수 있다.
이 장에서는 모델 평가의 다양한 방법과 교차 검증(Cross-Validation), 학습 곡선(Learning Curve)에 대해 다룬다.
4.6.1 교차 검증 (Cross-Validation)
교차 검증은 훈련 데이터의 일부를 검증 세트(validation set)로 사용하여 모델의 성능을 평가하는 방법이다. 이를 통해 훈련 데이터에 과적합된 모델이 아니라, 새로운 데이터에도 잘 일반화(generalize)될 수 있는 모델을 선택할 수 있다.
1. 데이터셋을 여러 개의 부분으로 나누고, 그 중 한 부분을 검증 세트로 사용한다.
2. 나머지 부분은 훈련 세트로 사용하여 모델을 훈련한다.
3. 검증 세트에서 성능을 평가한 후, 이 과정을 데이터를 모두 사용할 때까지 반복한다.
4. 최종적으로 모든 반복의 평균 성능을 평가하여 모델을 선택한다.
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
scores = cross_val_score(lin_reg, X, y, scoring="neg_mean_squared_error", cv=5)
rmse_scores = np.sqrt(-scores)
print("RMSE scores:", rmse_scores)
print("Average RMSE:", rmse_scores.mean())이 코드에서 cross_val_score 함수를 사용하여 5-fold 교차 검증을 수행하고, 각 폴드의 성능을 평균화하여 최종 평가 점수를 계산한다.
4.6.2 학습 곡선 (Learning Curve)
학습 곡선은 모델이 훈련 데이터의 크기에 따라 성능이 어떻게 변화하는지를 시각화한 그래프이다. 학습 곡선을 통해 과적합과 과소적합 여부를 파악할 수 있으며, 더 많은 데이터가 필요한지, 모델의 복잡도를 조절해야 하는지 판단할 수 있다.
- 과소적합(underfitting): 훈련 데이터가 충분하지 않거나, 모델이 너무 단순할 때 발생한다. 이 경우 훈련 및 검증 데이터 모두에서 성능이 낮다.
- 과적합(overfitting): 모델이 훈련 데이터에 너무 복잡하게 적합하여 새로운 데이터에 대해 일반화하지 못하는 경우 발생한다. 훈련 데이터에서는 높은 성능을 보이지만, 검증 데이터에서는 성능이 저하된다.
학습 곡선 그리기
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
train_sizes, train_scores, valid_scores = learning_curve(LinearRegression(), X, y, cv=5)
train_errors = -train_scores.mean(axis=1)
valid_errors = -valid_scores.mean(axis=1)
plt.plot(train_sizes, train_errors, "r-+", linewidth=2, label="Training error")
plt.plot(train_sizes, valid_errors, "b-", linewidth=3, label="Validation error")
plt.xlabel("Training set size")
plt.ylabel("RMSE")
plt.legend()
plt.show()이 코드를 통해 학습 곡선을 시각화할 수 있으며, 훈련 세트 크기에 따른 성능 변화를 확인할 수 있다. 학습 곡선은 모델의 복잡도와 데이터의 양에 따른 성능 변화를 쉽게 파악할 수 있는 도구이다.
4.6.3 하이퍼파라미터 튜닝 (Hyperparameter Tuning)
모델의 성능을 최적화하기 위해서는 하이퍼파라미터를 조정해야 한다. 하이퍼파라미터는 모델 훈련 전에 설정해야 하며, 교차 검증을 통해 적절한 값을 찾는 것이 일반적이다. 대표적인 하이퍼파라미터 튜닝 방법으로는 그리드 탐색(Grid Search) 과 랜덤 탐색(Random Search) 가 있다.
- 그리드 탐색(Grid Search): 사전에 정의된 하이퍼파라미터 값의 조합을 모두 시도하여 최적의 파라미터를 찾는 방법이다.
- 랜덤 탐색(Random Search): 그리드 탐색과 달리, 무작위로 하이퍼파라미터 값을 샘플링하여 최적의 파라미터를 찾는다.
그리드 탐색 구현 예시:
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import Ridge
param_grid = [
{'alpha': [0.1, 1.0, 10.0, 100.0]}
]
ridge_reg = Ridge()
grid_search = GridSearchCV(ridge_reg, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X, y)
print("Best parameters:", grid_search.best_params_)이 코드를 통해 하이퍼파라미터 alpha 값에 대한 최적의 값을 찾을 수 있다.
4.6.4 모델 선택 및 평가 지표
모델의 성능을 평가하기 위한 지표는 다양한 종류가 있다. 회귀 문제에서는 평균 제곱 오차(MSE, Mean Squared Error) 나 평균 절대 오차(MAE, Mean Absolute Error) 와 같은 지표를 많이 사용한다.
· MSE: 예측 값과 실제 값의 차이를 제곱한 후 평균을 구한 값. 값이 클수록 모델의 성능이 낮음을 의미한다.

· MAE: 예측 값과 실제 값의 차이의 절대값을 평균한 값으로, 모델의 예측 오류를 쉽게 해석할 수 있다.